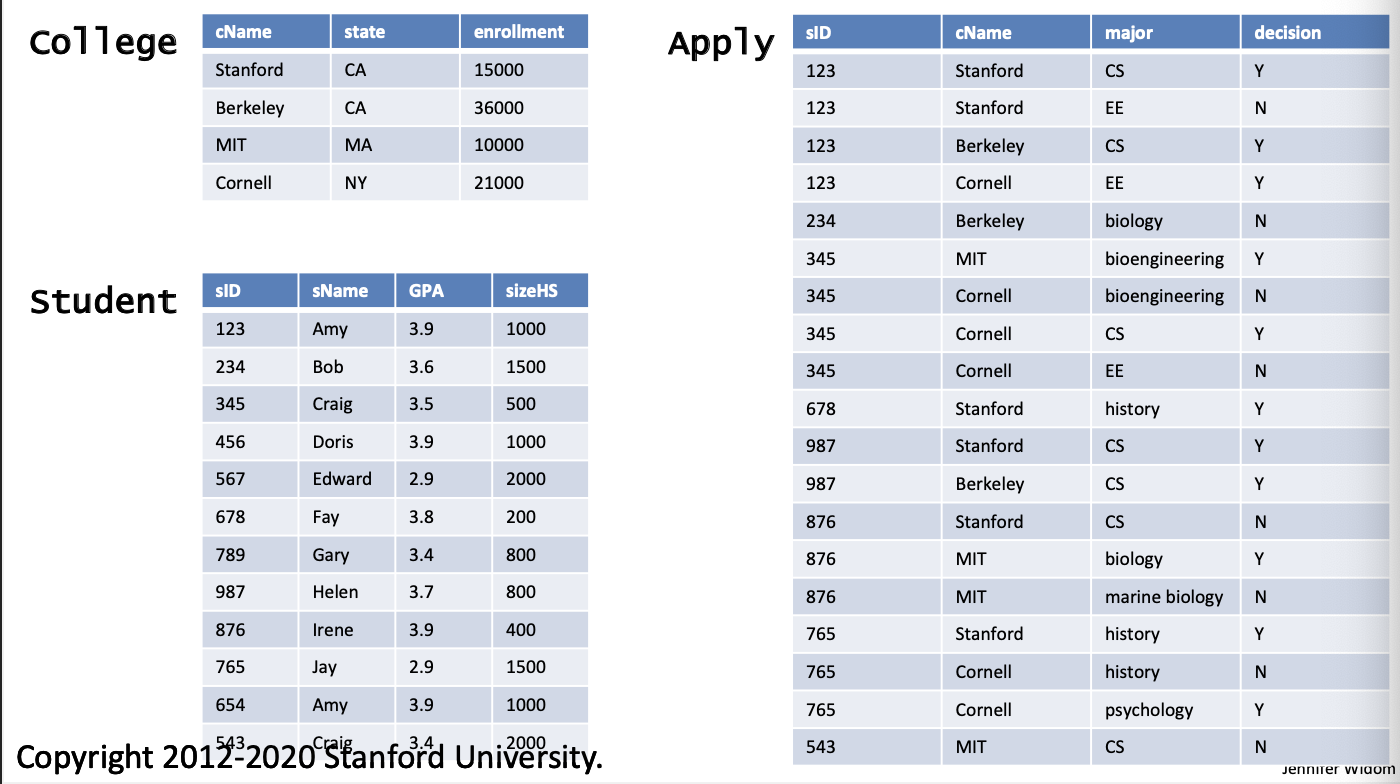
Subqueries in WHERE clause
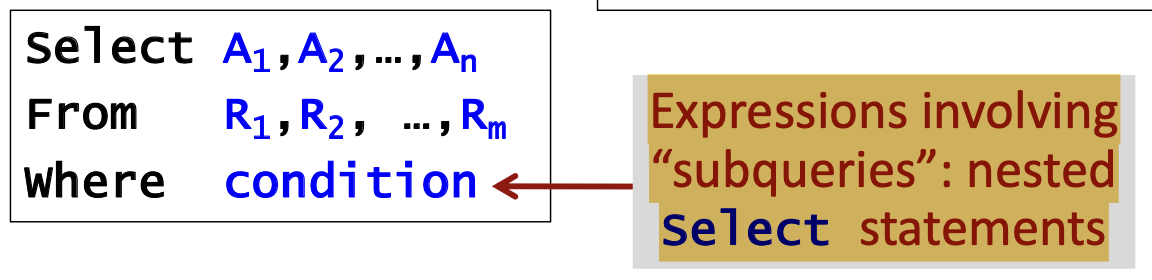
Select 문은 fig 1-2처럼 구성이 되는데 또다른 Select문을 Where문 안에 위치 시킬 수 있다. 그리고 이것을 서브쿼리라고 한다.
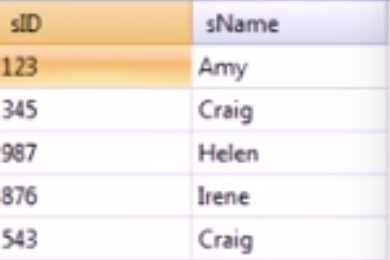
select sID, sName
from Student
where sID in (select sID from Apply where major = ‘CS’);결과만 보면 전공을 CS로 선택한 학생들의 ID와 이름을 가져온다. 굳이 이렇게 하지 않고 일반적인 select 문으로 고쳐보면 다음과 같다.
select distinct Student.sID, sName
from Student, Apply
where Student.sID = Apply.sID and major = ‘CS’;여기서는 sID를 Student.sID와 Apply.sID로 구분하고 있다. 만약 sID로 통일했다면 어느 테이블의 sID인지 명시하지 않았기 때문에 에러가 발생했을 것이다. 그리고 중복 결과가 발생할 수 있으므로 distinct도 사용해주고 있다. 또한 동명이인이 있을 수 있기 때문에 id도 같이 표시해주는 게 좋을 것 같다. 이렇듯 일반적인 select문이었다면 고려해야할 사항이 몇가지 있다.
반면에 where 안에 서브쿼리를 사용하게 되면 해당 쿼리는 바깥쪽 쿼리에게 독립된 쿼리, 즉 다른 연산이므로 sID를 그대로 사용할 수 있고, 서브쿼리의 결과에는 중복된 결과도 없으므로 distinct도 해줄 필요가 없다.
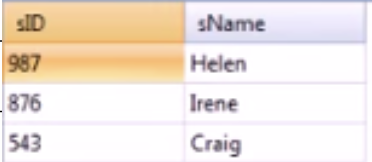
select sID, sName
from Student
where sID in (select sID from Apply where major = ‘CS’) and
sID not in (select sID from Apply where major = ‘EE’);select sID, sName
from Student
where sID in (select sID from Apply where major = ‘CS’) and
not sID in (select sID from Apply where major = ‘EE’);두개의 SQL 모두 CS 전공은 지원했지만 EE 전공에는 지원하지 않은 지원자의 sID와 sName을 반환한다.

select cName
from College C1
where not exists (select * from College C2
where C2.enrollment > C1.enrollment);다음은 복잡해보이지만 결과는 enrollment가 가장 큰 대학의 이름이다. for-each문을 생각하면 이해가 빠를 것이다. C1의 enrollment가 하나씩 'C2.enrollment > C1.enrollment'에 대입되면서 모든 C2의 enrollment와 비교연산이 되는데, 이때 C1의 가장 큰 enrollment가 들어가면 false가 반환될거고 그러면 not exists니깐 해당 enrollment에 해당하는 튜플의 cName이 선택되는 것이다. 이는 결국 enrollment가 가장 큰 대학의 튜플이 선택되는 것이다.
select sName
from Student S1
where GPA > all (select GPA from Student S2
where S2.sID <> S1.sID);이 sql은 GPA가 가장 높은 학생이름을 반환한다. 하지만 예제 데이터를 보면 4명의 학생이 가장 높은 GPA 3.9를 가진다. 그렇기 때문에 해당 쿼리의 결과는 텅 비어있다. 만약 GPA가 가장 높은 학생들이라는 결과를 얻고 싶으면 '>'가 아닌 '>='를 써야했다.
Subqueries in FROM and SELECT clauses
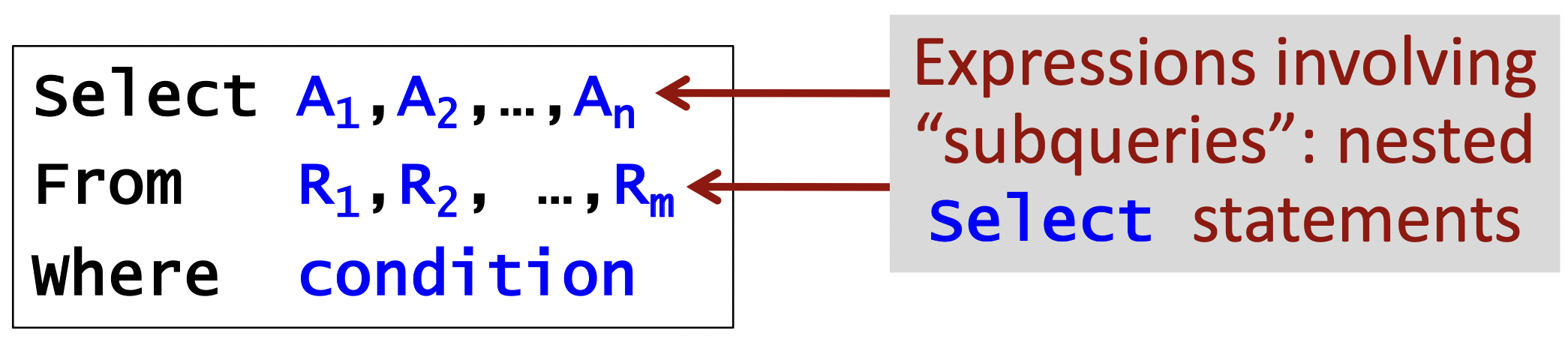
서브쿼리는 FROM과 SELECT문에도 넣어줄 수 있다.
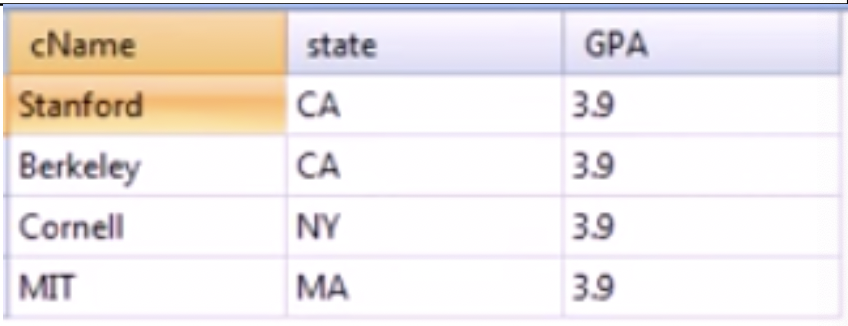
select distinct College.cName, state, GPA
from College, Apply, Student
where College.cName = Apply.cName and Apply.sID = Student.sID
and GPA >= all (select GPA from Student, Apply
where Student.sID = Apply.sID
and Apply.cName = College.cName);select cName, state,
(select distinct GPA
from Apply, Student
where College.cName = Apply.cName and Apply.sID = Student.sID
and GPA >= all (select GPA from Student, Apply
where Student.sID = Apply.sID
and Apply.cName = College.cName)) as GPA
from College; 벌써부터 한숨이 나온다,,, 두 개의 쿼리 모두 fig 3-2의 결과를 반환하는데, 첫번째 부터 살펴보자. 우선 바깥 Where 문만 빼보면 College, Apply, Student 테이블을 합친 다음 Where로 필터링하는 모양이다. 바깥 Where문 내부의 select 문을 살펴보면, 모든 GPA를 꺼내는 것을 알 수 있다. 정리하면 3개의 테이블을 합친 다음, 지원을 한 모든 학생들 중 가장 높은 GPA를 가진 학생들의 GPA, 지원한 대학의 이름과 지역을 뽑아내라 정도로 이해할 수 있다.
2번째 쿼리는 내부 쿼리를 빼고 보면 College의 cName과 state를 가져오면 된다. 하지만 내부 쿼리를 보면 Apply, Student를 합친 뒤 Where 조건에 따라 필터링하고 GPA만 반환한다. 그리고 그 조건은 위와 동일하게 모든 GPA에 대해 크거나 같은 튜플만 뽑아내는 것이다.
The JOIN family of operators

이번에는 JOIN 쿼리에 대해 살펴보자. JOIN 쿼리는 나눠보면 다음과 같다. 여기서 자주 쓰이는 일부만 보도록 하자.
- Inner Join On condition
- Natural Join
- Inner Join Using(attrs)
- Left | Right | Full Outer Join

select distinct sName, major
from Student, Apply
where Student.sID = Apply.sID;select distinct sName, major
from Student inner join Apply
on Student.sID = Apply.sID;select distinct sName, major
from Student join Apply
on Student.sID = Apply.sID;모두 fig 4-2와 같은 결과를 반환하는 쿼리문이다. 기존의 테이블을 연결시키는 방법과 동일한 결과를 가진다. 그리고 join과 inner join은 같은 의미라는 것을 알 수 있다. 여기서 on은 JOIN절을 위한 where과 비슷한 역할을 하는 조건절이다. on의 경우에는 join절이 실행되기 전에 수행이 된다는 점에서 where문과 차이가 있다.
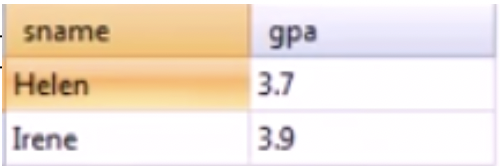
select sName, GPA
from Student, Apply
where Student.sID = Apply.sID
and sizeHS < 1000 and major = 'CS' and cName = 'Stanford';select sName, GPA
from Student join Apply
on Student.sID = Apply.sID
where sizeHS < 1000 and major = 'CS' and cName = 'Stanford';select sName, GPA
from Student join Apply
on Student.sID = Apply.sID
and sizeHS < 1000 and major = 'CS' and cName = 'Stanford';다음 쿼리문들은 sizeHS가 1000 미만이고, 전공은 CS이며 지원학교가 Stanford인 학생의 이름과 GPA를 가져온다. 2번째 3번째 쿼리문의 차이는 Where의 유무인데, 이렇게 on에 조건문들을 넣어줄 수 도 있다.

select Apply.sID, sName, GPA, Apply.cName, enrollment
from Apply, Student, College
where Apply.sID = Student.sID and Apply.cName = College;select Apply.sID, sName, GPA, Apply.cName, enrollment
from Apply join Student join College
on Apply.sID = Student.sID and Apply.cName = College.cName;
# 에러 발생 !!!!select Apply.sID, sName, GPA, Apply.cName, enrollment
from (Apply join Student on Apply.sID = Student.sID)
join College on Apply.cName = College.cName;3개의 테이블을 합치는 쿼리문들이다. 그런데 이런 작업에 join을 사용할 때 두번째 쿼리처럼 한번에 3개를 join하려고 하면 에러가 발생한다. 이러한 경우에는 3번째 쿼리처럼 2개씩 끊어서 join을 해주자.

select distinct sID
from Student natural join Apply;select distinct sID
from Student, Apply;
# 에러 발생 !!!!두 쿼리 모두 지원한 학생들의 sID를 얻으려고 한다. 하지만 첫번째 쿼리에 비해 두번째 쿼리는 에러가 발생한다. 첫번째 쿼리는 natural join을 썼기 때문에 결과 테이블에서 sID가 하나 없어지기 때문에 에러가 발생하지 않지만, 두번째 쿼리는 sID가 Student, Apply의 sID 중 어떤 것인지 알 수 없기 때문에 에러가 발생하게 된다.
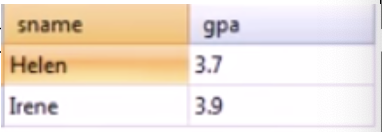
select sName, GPA
from Student join Apply
on Student.sID = Apply.sID
where sizeHS < 1000 and major = 'CS' and cName = 'Stanford';select sName, GPA
from Student natural join Apply
where sizeHS < 1000 and major = 'CS' and cName = 'Stanford';select sName, GPA
from Student join Apply using(sID)
where sizeHS < 1000 and major = 'CS' and cName = 'Stanford';fig 4-3와 같은 결과를 얻을 수 있는 쿼리들이다. 'from Student join Apply on Student.sID = Apply.sID'가 'from Student natural join Apply'와 'from Student join Apply using(sID)'와 같음을 알 수 있다. 즉 using을 통해 같은 이름을 가진 column 중 원하는 column에만 equal join을 수행할 수 있다.
참고로 using은 on과 같이 사용할 수 없다. 사용하게 되면 에러가 발생하게 된다.

select sName, sID, cName, major
from Student left outer join Apply using(sID); # 'outer'는 생략 가능select sName, Student.sID, cName, major from Student, Apply
where Student.sID = Apply.sID
union
select sName, sID, NULL, NULL
from Student
where sID not in (select sID from Apply);이번에는 다른 종류의 join인 left (outer) join이다. left join은 차집합 연산과 교집합 연산의 결과를 합친 것이다. 그러므로 Student와 Apply 테이블이 합쳐질 때, 모든 학생들의 튜플이 나오고 이때, 대학에 지원을 하지 않은 학생들의 cName과 major는 존재하지 않으므로 null이 된다.
이것을 set operation으로 표현하면 두번째 쿼리문과 같다. 위의 select문을 통해 대학에 지원한 학생들의 정보를 얻고 밑의 select문을 통해 대학에 지원하지 않은 학생들의 정보를 얻은 뒤 이를 합집합 연산해준 것이다.
right (outer) join은 left (outer) join과 방향만 다른 것이므로 넘어가자. 이제 full outer join을 알아보기 위해 2개의 Apply 테이블에 튜플을 추가한다.
insert into Apply values (321, 'MIT', 'history', 'N'); insert into Apply values (321, 'MIT', 'psychology', 'Y');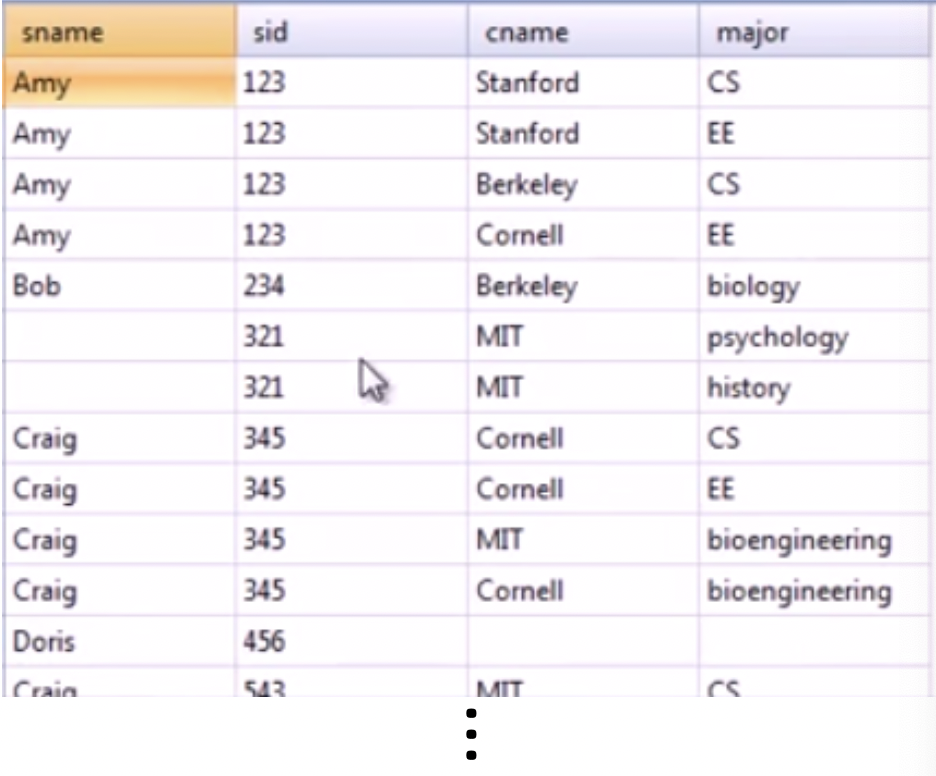
select sName, sID, cName, major
from Student full outer join Apply using(sID);select sName, sID, cName, major
from Student left outer join Apply
using(sID) union
select sName, sID, cName, major
from Student right outer join Apply using(sID);full outer join은 합집합 연산과 동일한 결과를 가진다. 그렇기 때문에 left join과 right join을 한 뒤 이를 합집합 연산한 것과 동일하다.
'데이터베이스' 카테고리의 다른 글
| Relational design theory (0) | 2022.11.03 |
|---|---|
| SQL 3 (0) | 2022.09.28 |
| SQL 1 (1) | 2022.09.19 |
| 관계대수(Relational Algebra) (0) | 2022.09.14 |
| 관계 모델(Relational Model) (0) | 2022.09.12 |




댓글