이번 글에서는 SQL에 대해서 다뤄볼 것이다. SQL은 모든 주요 상업 DBMS에서 사용이되며, 표준화되어있다. GUI나 프롬프트 등으로 상호작용이 가능하고 관계대수를 기반으로 declarative(선언형)한 프로그래밍 언어이다. 여기서 선언형이란 작업을 진행하기 위해 무엇을 진행할 것인지를 나열하는 것이다. 명령형 프로그래밍 언어인 c나 java처럼 작업을 어떻게 하는지 정의하지는 않는다.
SQL은 몇 종류의 명령어로 나눌 수 있는데, 이전에 설명한 DDL, DML과 기타 명령어(index, constraints, ...)로 나눌 수 있다. 시작하기 전에 가장 자주 쓰이는 SELECT문의 형태를 예시로 보자.
Select A1, A2, ..., An
From R1, R2, ..., Rm
Where condition이것을 저번에 학습한 관계대수로 표현하면 다음과 같이 나타낼 수 있다.
$$\pi_{A1, A2, ..., An}(\sigma _{condition}(R1, R2, ..., Rm))$$

이제부터 간단한 대학 지원 데이터베이스를 예시로 하여 진행해보자. 우선 fig 1과 같은 테이블을 만들어야 하므로 DDL을 사용해야 한다.
create table College(cName varchar(20), state char(2), enrollment int,
primary key(cName));
create table Student(sID int, sName varchar(20), GPA numeric(2,1), sizeHS int,
primary key(sID));
create table Apply(sID int, cName varchar(20), major varchar(20), decision char,
primary key(sID, cName, major),
foreign key(sID) references Student(sID),
foreign key(cName) references College(cName));우선 테이블들을 생성하고 각 테이블의 key attribute를 설정해주고 있다. Apply같은 경우엔 sID, cName, major가 합쳐져서 key를 이룬다. 그리고 Apply 테이블에서 sID와 cName을 외래키(foreign key)로 설정하는데, 외래키는 두 테이블을 연결할 때, 다른 테이블의 기본키를 참조한다.
이후 'Insert into College values('Stanford', 'CA', 15000)'같은 insert문을 이용하여 fig 1처럼 되도록 초기 데이터를 채울 수 있다. 이제 준비는 다 되었고 이것들을 사용하여 SQL을 익혀보자.
Select Statement

select sID, sName, GPA
from Student
where GPA > 3.6;SQL은 영어를 해석하듯이 이해하면 되는 것 같다. 위와 같은 SQL을 실행하면 fig 2-1같은 결과를 얻을 수 있다. 'Student 테이블에서 GPA가 3.6보다 큰 튜플 증에서 sID, sName, GPA만 가져와라' 정도로 해석할 수 있고 실제로 그러한 결과가 가져와진다.
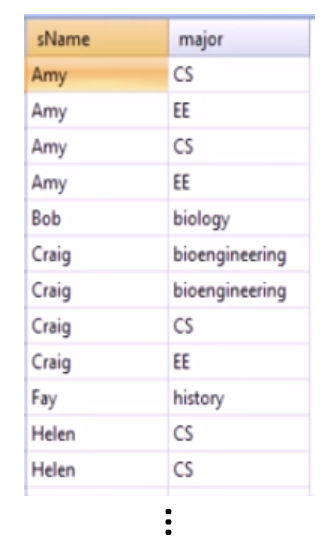
select sName, major
from Student, Apply
where Student.sID = Apply.sID;이 쿼리는 Student, Apply 두개의 테이블을 선택했다. 그리고 위에서 말했지만 Apply 테이블은 Student 테이블의 기본키인 sID을 외래키로 가진다. 그렇기 때문에 where 뒤에 'Student.sID = Apply.sID'를 통해 두 테이블을 연결할 수 있다. 결과 테이블에서 sName과 major는 키가 아니기 때문에 중복이 발생할 수 있다. 만약 중복을 제거한 결과를 얻고 싶다면 select 앞에 'distinct'를 붙여주자.

select distinct sName, major
from Student, Apply
where Student.sID = Apply.sID;
select sName, GPA, decision
from Student, Apply
where Student.sID = Apply.sID and sizeHS < 1000 and major = ‘CS’ and cName = ‘Stanford’;이렇게 where 뒤에 다양한 조건들을 추가하여 필터링 할 수 있다.
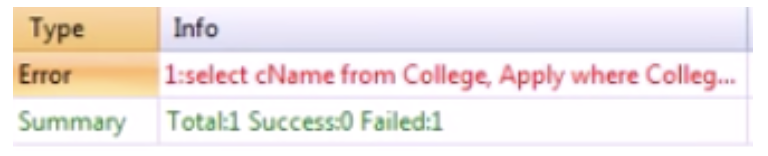
select cName
from College, Apply
where College.cName = Apply.cName and enrollment > 20000 and major = ‘CS’;다음과 같은 SQL 쿼리를 날리면 오류가 발생한다. 왜냐하면 College, Apply 테이블 모두 cName이라는 attribute를 갖고 있는데 둘중에 어느것을 select할지 특정하지 않았기 때문이다. 그렇기 때문에 이런 경우에는 'College.cName'처럼 어떤 테이블의 attribute인지 정해줘야 한다.
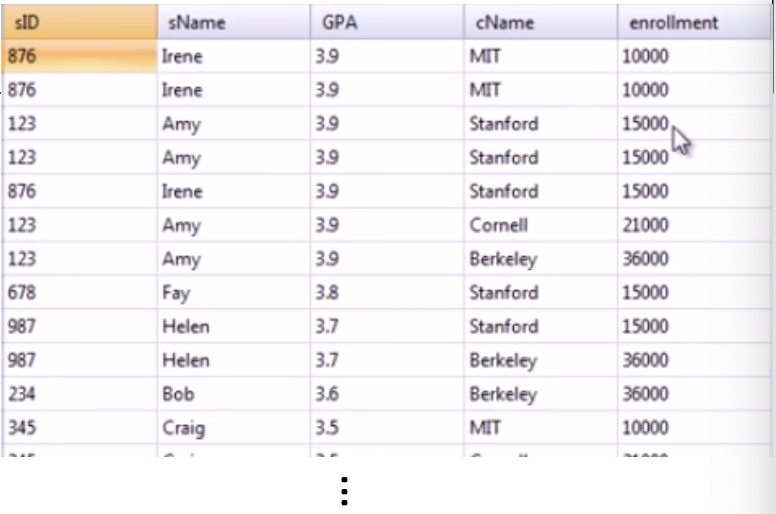
select Student.sID, sName, GPA, Apply.cName, enrollment
from Student, College, Apply
where Apply.sID = Student.sID and Apply.cName = College.cName;
order by GPA desc, enrollment;여기서는 Apply와 Student를 sID로, Apply와 College를 cName으로 하여 3개의 테이블을 연결하고 있다. 만약 특정 attributes를 기준으로 결과를 정렬하고 싶다면 'order by (attribute) desc/asc, ...'을 하면된다. 기본값은 asc이며 ','를 기준으로 attribute를 여러개 지정할 수 있다.
fig 2-6에서는 우선 GPA를 기준으로 내림차순으로 정렬하고 같은 GPA를 가지는 튜플들끼리는 enrollment를 기준으로 오름차순으로 하여 정렬이 된다.

select sID, major
from Apply
where major like ‘%bio%’;다음 구문처럼 attribute 중 특정 내용이 포함된 튜플을 찾을 수도 있다.
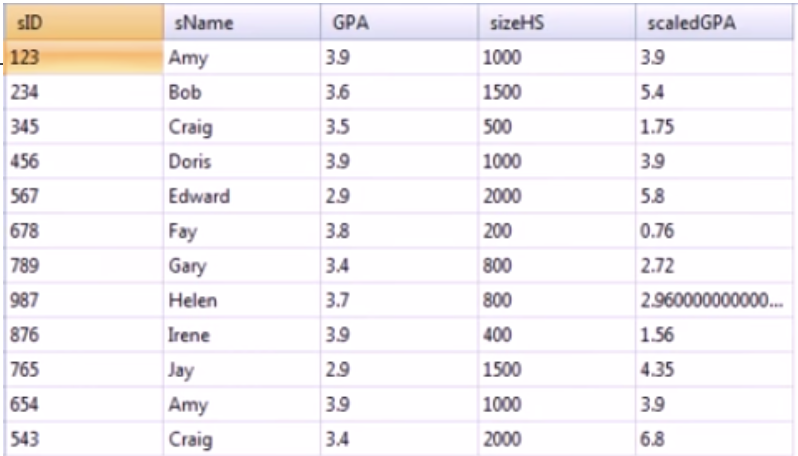
select sID, sName, GPA, sizeHS, GPA*(sizeHS/1000.0) as scaledGPA
from Student;위와 같은 쿼리는 각 튜플에서 GPA*(sizeHS/1000.0)을 값으로 하는 새로운 attributes가 추가되는데, 이때 'as'를 사용하여 해당 attribute의 이름을 설정할 수 있다. as를 사용하지 않으면 attribute 이름은 그대로 'GPA*(sizeHS/1000.0)'가 된다.

select *
from Student, College;'*'은 전체를 선택한다는 뜻이다. 여기서는 Student와 College의 모든 attibutes를 가져오는 것을 확인할 수 있다.
Table Variables and Set Operation
Table Variables
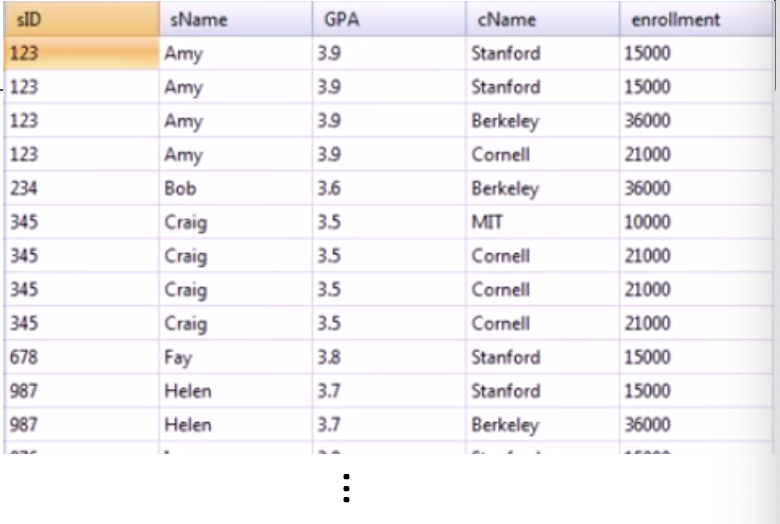
select Student.sID, sName, GPA, Apply.cName, enrollment
from Student, College, Apply
where Apply.sID = Student.sID and Apply.cName = College.cName;select S.sID, sName, GPA, A.cName, enrollment
from Student S, College C, Apply A
where A.sID = S.sID and A.cName = C.cName;where ~ 부분을 보면 Apply를 기준으로 Studnet, College 테이블이 연결되어 있다. 이 때 각 테이블에 새롭게 이름을 설정해 줄 수 있다. select나 where 작성 시 편리할 것 같은데 이것을 사용하는 다른 이유는 없을까?
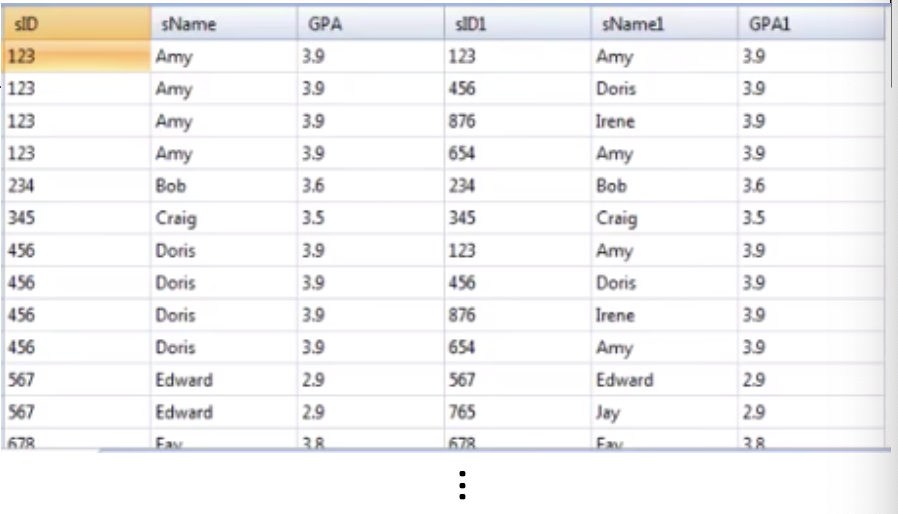
select S1.sID, S1.sName, S1.GPA, S2.sID, S2.sName, S2.GPA
from Student S1, Student S2
where S1.GPA = S2.GPA;다음과 같이 self join을 했을 때는 'Student.GPA = Student.GPA'라고 하면 오류가 발생하기 때문에 각각 테이블에 S1, S2라는 이름을 붙여줘서 aliasing을 통해 동일한 종류의 테이블을 구분해주고 있다. 여기서 자기자신과 GPA가 같은 튜플은 크게 의미가 없기 때문에 이를 없애줘야 한다.
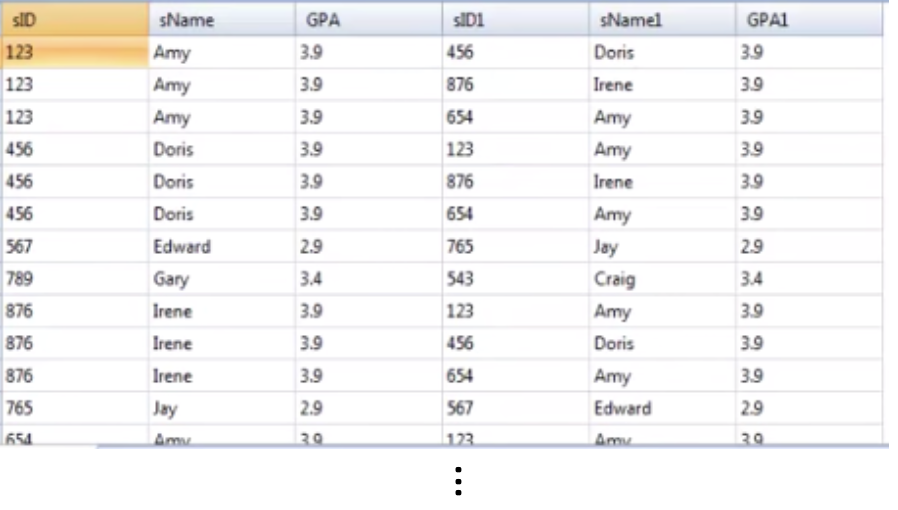
select S1.sID, S1.sName, S1.GPA, S2.sID, S2.sName, S2.GPA
from Student S1, Student S2
where S1.GPA = S2.GPA and S1.sID <> S2.sID;'<>'라는 새로운 기호가 눈에 띈다. 위에 결과를 보면 알겠지만, 이 기호는 프로그래밍에서 쓰는 '!='(같지 않다)와 같은 의미로 생각하면 된다. 시키는 기호이다.
Set Operation
SQL의 set operation에 대해 알아보자. 저번 글에서 봤겠지만 두 테이블을 대상으로 하는 연산이다.

select cName as name from College
union
select sName as name from Student;College의 대학 이름과 Student의 학생이름을 합집합 연산한 결과이다. 이때 '~ as {attribute 이름}'을 통해 결과 테이블의 attribute 이름을 설정해주고 있다. 그리고 set operation의 결과는 중복이 없다. 만약 중복 결과를 없애고 싶지 않다면 union all을 사용하자.

select sID from Apply where major = ‘CS’
intersect
select sID from Apply where major = ‘EE’;다음은 교집합 연산을 통해 CS와 EE를 모두 전공을 하는 경우에 대한 결과이다. 이를 단순 select 문을 이용하여 나타낼 수 도 있다.
select distinct A1.sID
from Apply A1, Apply A2
where A1.sID = A2.sID and A1.major = ‘CS’
and A2.major = ‘EE’;distinct가 없었다면 중복이 발생했을 것이다.

select sID from Apply where major = ‘CS’
except
select sID from Apply where major = ‘EE’;차집합 연산을 통해 CS를 지원한 학생들 중 EE를 지원한 학생들을 다 제외한 결과이다. 이것 역시 위 처럼 select 문으로 표현할 수 있을까?

select distinct A1.sID
from Apply A1, Apply A2
where A1.sID = A2.sID and A1.major = ‘CS’ and A2.major <> ‘EE’;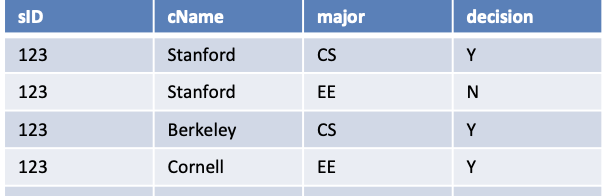
조건 그대로 표현한 것 같지만 그렇지 않다. 예를 들어 '123'이 있게 된 이유를 살펴보자. 2개의 Apply 테이블이 연결되는데, 단순히 연결만 된다면 총 4 * 4 = 16개의 쌍이 만들어질 수 있다. 그 중에는 'CS' - 'CS'인 튜플도 나오는데 이는 where 조건에 부합한다. 그렇기 때문에 fig 3-7처럼 의도와는 다른 결과가 나올 수 있다.
그러므로 set operation을 select 문으로 옮길 때는 주의가 필요하다.
'데이터베이스' 카테고리의 다른 글
| Relational design theory (0) | 2022.11.03 |
|---|---|
| SQL 3 (0) | 2022.09.28 |
| SQL 2 (0) | 2022.09.23 |
| 관계대수(Relational Algebra) (0) | 2022.09.14 |
| 관계 모델(Relational Model) (0) | 2022.09.12 |




댓글