이 카테고리의 글 들은 아주대학교 변광준 교수님의 '데이터베이스' 수업을 수강하고 복습 겸 정리하는 글이다. 이 수업은 관계형 DB에 대해 다루게 된다. 첫 시간은 관계형 모델에 대한 내용이다.
우선 관계형 모델은 대부분의 주요 사용 DB 시스템에서 사용된다. 간단한 형태의 모델을 가지며 고급 언어를 이용한 단순한 쿼리를 이용하여 효율적으로 DB 시스템을 구현할 수 있다.
관계형 모델의 구성
그럼 관계형 모델이 어떤 구조로 구성이 되는지 알아보자. 유의어가 많아서 생각보다 헷갈린다.
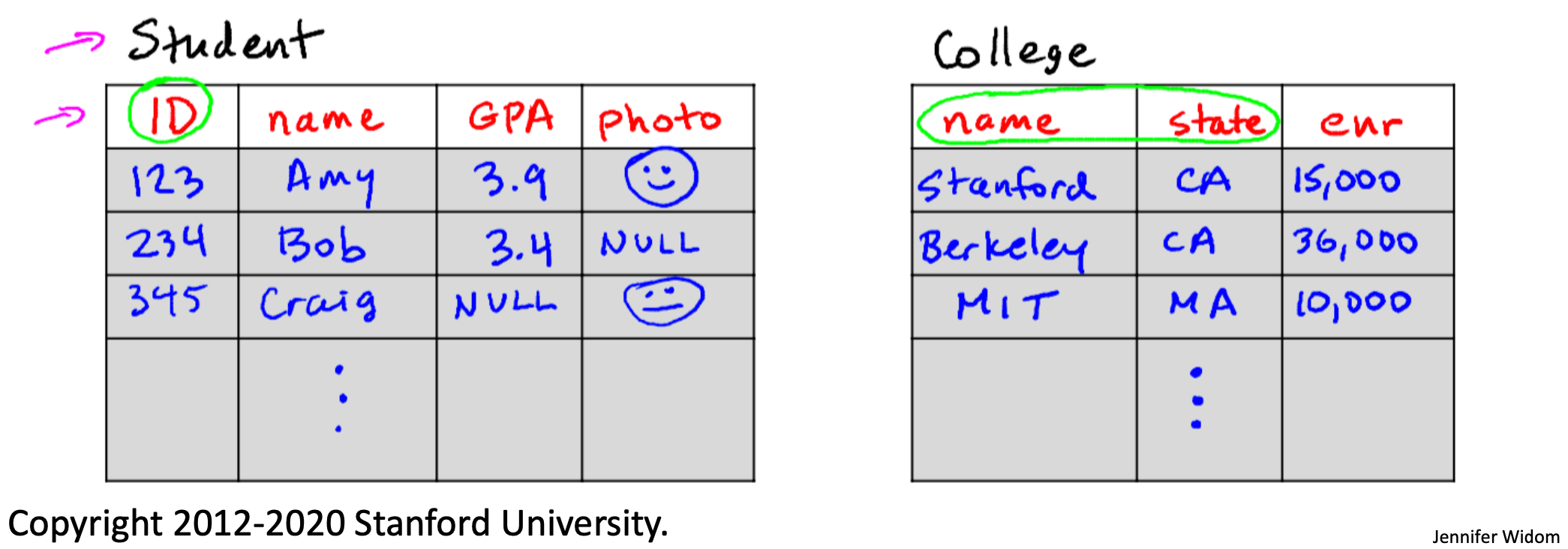
- Scehma: 스키마란 데이터베이스의 관계에 대한 구조적 설명이다. fig 1을 보면 Student 테이블의 스키마는 id, name, GPA, photo이고, College 테이블의 스키마는 name, state, enr이다. 이것을 보고 각 테이블이 ~한 정보를 가지거나, ~한 정보를 가져야 한다는 제약조건 등을 알 수 있는 것이다.
- Instance: 스키마에 값들이 실제로 정의되는 값들을 인스턴스라고 한다. Student, College 테이블의 스키마에 따라 id, name state, ... 등의 데이터가 실제로 담긴다.
- Database: 데이터베이스는 정의된 relation(= table)의 집합이다. fig 1 같은 테이블들이 여러개 모이면서 데이터베이스를 형성한다.
- 각 relation에는 정의된 attributes(= columns)이 있다.
- 각 tuple(= row)에는 각 속성에 대한 값이 있다.
- 각 attribute는 type(=domain)을 가진다. 예를 들어 id는 숫자형 데이터가 들어가겠지만, name에는 문자형 데이터가 들어가야 할 것이다.
- Null: unknown, undefined같은 의미의 특별한 값이다. fig 1에서 Bob의 photo 정보를 넣지 않았다면 해당 데이터를 Null로 표시된다.
- Key: 각 튜플(row)이 갖는 attributes 중 unique한 값을 갖는 attribute나 합쳐졌을 때 unique한 값을 갖게되는 attributes의 집합이다. fig 1의 Student 테이블은 ID라는 key를 가짐으로써 다른 튜플들과 구별될 수 있고, College 테이블은 name, state라는 2개의 attributes가 key가 되어 다른 튜플들과 구별될 수 있다.
Relation(Table) 생성 SQL
참고로 SQL은 관계형 데이터베이스 관리 시스템의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어이다. 쉽게 말하면 DB를 다루는 언어이다. 테이블을 생성하는 SQL은 다음과 같은 형태이다.
Create Table Student(ID, name, GPA, photo)
Create Table College (name string, state char(2), enrollment integer)Student 테이블을 생성하는 SQL은 테이블의 이름과 attributes를 선언하고 있다. College를 생성하는 테이블은 attibutes와 attributes의 type도 선언해주고 있다. 이러한 종류의 언어를 DDL(Data Definition Language)이라고 할 수 있겠다. 말 그대로 데이터(DB)를 정의하는 언어이다.
Querying Relational Databases
대학 원서 제출 서비스를 예시로 들면서, 여기선 관계형 DB를 사용하는 과정에 대해 알아보자. 보통 다음과 같은 과정을 통해 관계형 DB를 사용한다.
- 스키마를 디자인하고, DDL을 사용하여 생성한다.
- 초기 데이터를 로드한다.
- 쿼리를 실행하면서 데이터를 수정하는 작업을 반복한다.
어쨌든 DB의 사용목적은 데이터를 저장하고 필요할 때 꺼내쓰기 위함이니 1., 2.을 통해 한번 만들어 놓은 이후에는 3.을 반복하면서 데이터를 수정하거나 불러오면서 서비스를 돌린다.
3. 과정에는 다음과 같은 예시가 있을 것이다.
– Stanford 및 MIT에만 지원하는 GPA > 3.7인 모든 학생
– 지원자가 500명 미만인 CA의 모든 엔지니어링 부서
– 최근 5년간 평균 합격률이 가장 높은 대학.
당연하겠지만 SQL은 데이터 수정에도 사용된다. 이를 DML(Data Manipulation Language) 즉 데이터 조작어라고 한다. SQL을 이용하여 쿼리를 날리면 테이블을 반환한다. 예를 들어 'Stanford 및 MIT에만 지원하는 GPA > 3.7인 모든 학생'을 구하기 위한 쿼리를 날리면 해당하는 학생들에 대한 테이블이 반환되는 것이다.
다음 글에서 자세히 알아볼 것이지만 'Stanford에 지원하는 GPA > 3.7인 모든 학생의 id'를 관계대수(Relational Algebra)로 나타내보면 $$\pi_{id} \sigma_{GPA>3.7 \wedge CName='Stanford'}(Student\bowtie Apply)$$로 나타낼 수 있고, SQL로 나타내보면 다음과 같다.
Select Student.ID
From Student, Apply
Where Student.ID=Apply.ID
And GPA>3.7 and college=‘Stanford
'데이터베이스' 카테고리의 다른 글
| Relational design theory (0) | 2022.11.03 |
|---|---|
| SQL 3 (0) | 2022.09.28 |
| SQL 2 (0) | 2022.09.23 |
| SQL 1 (1) | 2022.09.19 |
| 관계대수(Relational Algebra) (0) | 2022.09.14 |




댓글