그전까지는 관계대수나 SQL을 통해 DB의 데이터들을 어떻게 다루는지에 대해 알아보았다. 해당 파트에서는 관계형 DB를 어떻게 효율적으로 설계할 수 있는지에 대한 내용을 다룰 것이다. 동일한 내용의 데이터를 담아도 테이블들이 어떻게 설계되는지에 따라 전체적인 구조가 크게 달라질 수도 있기 때문이다.
Rel Design Overview
이 글에서는 대학 지원 정보와 관련된 데이터를 예시로 들면서 각 개념을 설명할 예정이다.
Apply(SSN, sName, cName, HS, HScity, hobby)대충 파악이 되겠지만, Apply에는 사회 보장 번호(SSN, PK), 학생 이름, 대학 이름, 고등학교 이름, 고등학교가 속한 지역, 학생의 취미 정보들이 담겨있다.
이때 다음과 같은 경우가 있다고 생각해보자.
123 Ann from PAHS (P.A.) and GHS (P.A.) plays tennis and trumpet and applied to Stanford, Berkeley, and MIT
Ann이라는 한 명의 학생은 P.A. 지역의 PAHS, GHS 학교 출신이고 취미는 테니스, 트럼펫이며, 스탠포드, 버클리, MIT에 지원하였다. 가장 단순하게 생각해보면 이 케이스를 한 테이블로 모두 표현하려면 12(2*2*3)개의 tuple이 필요할 것이다. 당연히 말은 되지만 딱봐도 뭔가 비효율적인게 느껴진다. 다음과 같이 설계를 했을 때 막연하게 느껴지는 이상함을 한번 명확하게 뜯어보자.
참고로 잘못된 DB 설계는 전체적인 무결성이 저하되는데 이는 이상 현상(Anomaly)에 의해 발생된다. 밑에서 몇가지 언급하겠지만 이 이상 형상은 몇 가지 유형이 있다.
Redundancy
우선 데이터 중복(Data Redundancy)이 발생한다. 왜냐하면 취미, 지원 학교 등 하나의 속성만 바뀌어도 튜플이 추가되어야 하기 때문에 중복되는 정보가 많게 된다. 이는 일관된 자료 처리가 어렵고, 저장 공간이 낭비되기 때문에 데이터 효율성이 떨어진다.
Anomaly
Update Anomaly
이제 어떤 종류의 anomaly들이 해당 설계에서 발생할 수 있는지 살펴보자. 우선 update anomaly가 존재할 수 있다. 이는 데이터의 특정 데이터를 업데이트 했는데, 정상적으로 변경이 되지 않거나 너무 많은 행을 업데이트하는 경우다. 예를 들어 Ann 학생의 지역을 P.A.가 아닌 다른 지역으로 변경하게 되면 12개의 행을 모두 업데이트 해야 한다.
Deletion Anomaly
deletion anomaly는 특정 정보를 삭제하면 원치 않는 정보도 삭제가 되버리는 현상이다. 예를 들어 지원 학교가 버클리인 경우를 모두 지워버리면 버클리 대학에 대한 정보를 따로 저장하지 않았기 때문에, 버클리 대학의 정보가 모두 삭제되버리는 것이다.
Insertion Anomaly
추가적으로 insertion anomaly라는 것이 있는데 이는 삽입할 데이터에 특정 데이터가 존재하지 않아 데이터를 DB에 삽입할 수 없을 때 발생한다. 취미나 지원대학에 대한 정보를 db에 추가하고 싶은데 이때 SSN, 학생에 대한 정보가 없다고 하면 데이터를 추가할 수 없게 된다. 왜냐하면 학생에 대한 SSN이 해당 테이블의 PK이기 때문이다.
Designed by Decomposition
위에서 발생하는 문제들은 데이터를 하나의 테이블에 두는게 아니라 몇 개의 테이블로 분리시켜 저장하면 해결될 수 있다. 극단적으로 생각해보면 학생, 지원 대학, 고등학교, 고등학교 위치 지역, 취미를 모두 각각의 테이블로 분리할 수 있을 것이다.
Student(SSN, sName)
Apply(SSN, cName)
HighSchool(SSN, HS)
Located(HS, HScity)
Hobbies(SSN, hobby)
이렇게 하면 위에서 말한 anomaly가 대부분 해결되는 것을 확인할 수 있을 것이다. 하지만 뭔가 데이터들을 너무 잘게 쪼갠거 같은 느낌도 난다. 그래서 큰 문제가 없다면 몇몇 데이터는 합쳐도 된다. 예를 들어 고등학교가 속한 지역은 여러 개가 될 수는 없기 때문에 'HighSchool(SSN, HS, HScity)'로 합쳐도 문제가 되지 않는다.
이렇듯 분해(decomposition)를 통해 db를 디자인 할 수 있다. 처음에는 모든 데이터를 포함한 'mega' relation으로 시작해서 더 작고 나은 relation으로 분해하면 된다. 그리고 이러한 분해과정은 정규화를 통해 정해진 절차에 따라 진행가능하다.
Functional Dependency
정규화에 대해 알아보기 전에 함수적 종속성을 간단히 이해하고 넘어가자.
| SSN | sName | cName |
| 123 | Ann | Stanford |
| 345 | John | Berkely |
다음과 같은 경우에는 SSN에 의해 sName과 cName은 구분이 되므로 sName과 cName은 SSN에 함수적으로 종속되어 있다고 할 수 있다.
| SSN | sName | HScity | HS |
| 123 | Ann | A | PAHS |
| 345 | John | B | GHS |
해당 테이블에서 함수적 종속성을 파악하면 다음이 있다.
- SSN -> sName
- {SSN, HScity} -> HS
- {SSN, HScity} -> sName
sName은 속성집합인 {SSN, HScity}와도 함수적으로 종속될 수 있지만 {SSN, HScity}의 부분집합인 SSN만으로도 함수적으로 종속되는데 이 같은 경우를 부분 함수적 종속(Partial Functional Dependency)이라고 한다. 반면 HS는 {SSN, HScity}의 어떤 부분집합으로도 함수적으로 종속될 수 없는데 이를 완전 함수적 종속(Full Functional Dependency)이라고 한다. 보통 함수적 종속성을 말할 때는 완전 함수적 종속을 말하는 것이다.
Fourth Normal Form
우선 multivalued dependency, 즉 중복을 최소하게 데이터를 구조화하는 Fourth Normal Form부터 살펴보자. 좀 어렵게 말하면 함수적 종속성을 이용해 연관있는 속성들(properties)을 분류하고 각 relation들에서 이상현상이 생기지 않도록 하는 과정이다. 정규화된 정도를 정규형(Normal Form, NF)이라고 하는데 정규형에는 1NF, 2NF, 3NF, BCNF, ..., 6NF까지 있다. 보통 3NF가 되었으면 정규화가 되었다고 할 수 있는데 대부분의 테이블에서 이상현상이 발견되지 않는다.
제1정규형(1NF)
1NF는 relation에 대한 모든 속성의 도메인이 원자 값으로 구성되어 있는 경우이다. 즉 한 셀에 하나의 데이터만 들어가야 한다.
| SSN | sName | cName |
| 123 | Ann | Stanford, Berkely, MIT |
그렇기 때문에 위와 같은 경우는 1NF를 만족하지 않는다.
| SSN | sName | cName |
| 123 | Ann | Stanford |
| 123 | Ann | Berkely |
| 123 | Ann | MIT |
이런 모양은 되어야 1NF를 만족하게 된다. 관계형 DB의 테이블에서는 모든 properties가 원자 값을 가져야 하기 때문에 적어도 1NF는 만족해야 relation이 될 수 있다.
제2정규형(2NF)
1NF를 만족시키는 relation에서 부분 함수적 종속성을 가지는 경우 위에서 말한 3가지의 이상현상이 모두 나타날 수 있다. 다르게 말하면 2NF에서는 PK가 아닌 모든 attribute들은 PK에 완전 함수적 종속성을 가져야 한다는 뜻이다. 예를 들어 SSN과 sName을 PK로 잡았는데 SSN만으로도 모든 튜플을 구분할 수 있다면 이는 부분 함수 종속성을 가지게 되는 것이므로 제 2NF를 만족하지 못한다.
하지만 제 2NF를 만족시킨다고 해도 이상현상들이 사라지는 것은 아니다. 2NF에서는 삽입이상, 갱신이상, 삭제이상이 발생할 수 있다. 이는 이행적 함수 종속이 존재하기 때문인데, 이를 제거하는 과정이 제3정규화이다.
제3정규형(3NF)
이행적 함수 종속이란 삼단논법을 생각하면 된다. A->B이고, B->C라면, A->C가 성립한다. 이때 C가 A에 이행적으로 함수 종속되었다고 한다. 만약 한 테이블에 A, B, C가 모두 존재한다면 이행적 함수 종속이 발생할 수 있다는 것이다.
그러므로 이를 해결하기 위해서는 [A, B, C]를 [A, B], [B,C] 두 relation으로 분리하면 된다. 하지만 3NF까지 만족하여도 이상현상이 발생할 수 있는데 기본키가 될 수 있는 후보키가 여러개인 경우이다. 이를 해결하기 위한 정규형이 BCNF(Boyce-Codd Normal Form)이다.
BCNF
이론적으로 BCNF는 다음과 같다.
X -> Y는 trivial FD이거나, X는 relatioin R의 슈퍼키이다.
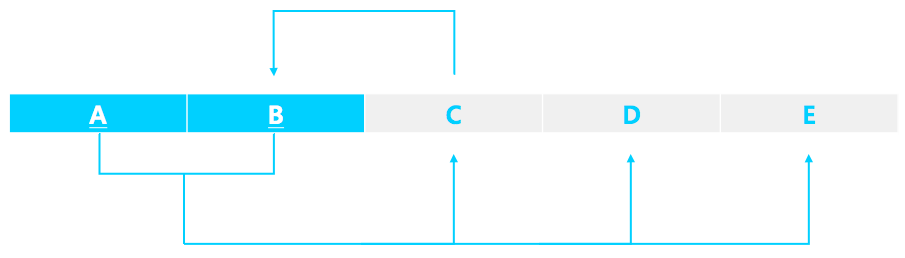
trivail FD는 Y가 X의 부분집합인 경우이다. 다르게 말하면 모든 결정자가 key인 경우를 BCNF라고 할 수 있다. fig 1을 보면 기본키 이외의 속성들이 기본키에 완전 함수 종속하고 이행적 함수 종속이 되지 않는다. 1NF를 만족한다는 가정하에 2NF, 3NF도 만족하는 것이다. 하지만 결정자인 C가 슈퍼키가 아니게 되므로 BCNF가 되지는 못하는 것이다.
fig 1에서 A, B, C로만 구성된 테이블이 있다 가정하고 BCNF를 이루지 못하는 relation에 대한 분해과정은 다음과 같다.
- BCNF를 위반하는 nontrivial FD C -> B를 찾는다.
- C, B로 이루어진 relation, C와 나머지 속성들로 구성된 relation을 분해한다.
즉 기존 relation에서 결정자 역할을 했던 속성을 키로 만들어주는 것이다.
참고 자료
'데이터베이스' 카테고리의 다른 글
| 트랜잭션(Transaction) (0) | 2022.12.10 |
|---|---|
| SQL 3 (0) | 2022.09.28 |
| SQL 2 (0) | 2022.09.23 |
| SQL 1 (1) | 2022.09.19 |
| 관계대수(Relational Algebra) (0) | 2022.09.14 |



댓글