저번 게시글에서는 계산 복잡도 이론에 대해 간단히 알아보고 이에 대한 개념을 일부 정렬 문제에 적용해보았다. 이번에는 탐색 문제에 계산 복잡도 이론을 적용해보자. 다음과 같은 사항들을 이번에는 알아볼 것이다.
- 키 비교를 이용하는 배열 탐색에 대한 하한
- 선택 문제: Adversary Arguments 소개
- K번째 가장 작은 키 찾기
- 선택 문제에 대한 확률적 알고리즘
The Searching Problem
탐색 문제는 일부 키 필드의 값을 기준으로 전체 레코드를 검색하는 것을 말한다. 예를 들어보자. 레코드는 개인 정보로 구성되고 키 필드는 주민등록번호라고 할 수 있다. 그렇다면 우리는 해당 키 필드를 이용하여 레코드를 탐색할 수 있는 것이다. 이전에 다뤄본 정렬 문제와 마찬가지로 탐색 문제에서도 하한을 계산해 볼 수 있다.
Lower Bounds for Searching only by Comparisons of keys
우선 검색 문제에 대해 정의해보자. n개의 키와 키 x를 포함하는 배열 S가 주어지고 'x=S[i]'가 되는 인덱스 i를 찾아야 한다. 만약 x가 S에 없다면 실패를 반환해야 한다.
우선 이진 탐색 알고리즘으로 확인해보자. 해당 알고리즘은 배열이 정렬되어 있을 때, 문제를 해결하는데 매우 효율적이다(참고). worst-case 시간 복잡도는 \(logn\)이었다. 여기서 한가지 질문이 있다. 키 비교로만 검색하는 알고리즘으로 제한했을 때 이진 탐색의 시간 복잡도인 \(logn\)보다 나은 알고리즘을 개발할 수 있을까? 정답은 No이다. 탐색 문제의 하한은 \(\Omega(logn)\)이기 때문이다. 이유는 뒤에서 알아보자.
정렬 알고리즘과 유사하게 비교 기반의 탐색 알고리즘은 n개의 키의 배열 S에서 주어진 키 x를 컴색하는 것에 해당하는 결정 트리를 가지고 있다.
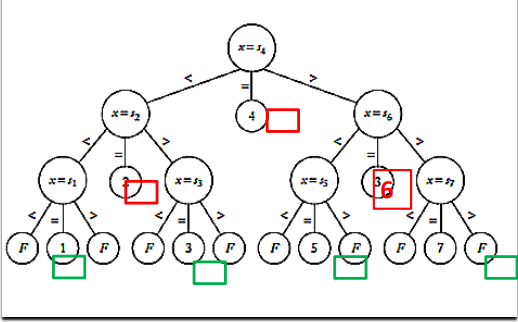
fig 1이 그것이다. 인덱스 i또는 실패(F)를 반환한다. 7개의 키가 있는 배열의 이진 탐색 알고리즘에 해당하는 결정 트리이다. 내부 노드(root, leaves 제외)는 3개의 자식 노드를 가진다(<, =, >).
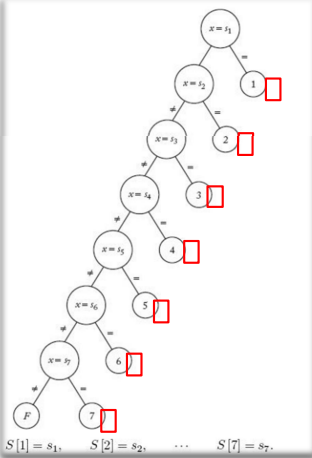
fig 2는 가장 간단한 탐색 알고리즘인 선형 탐색 알고리즘에 해당하는 이진 결정 트리이다. fig 1과 똑같이 7개의 키가 있는 배열에 대한 것이다.
위의 2개의 예시를 통해 우리는 n개의 키가 있는 데이터 구조(배열)에서 키 x를 검색하기 위해 가능한 각 결과에 대해 루트 노드에서 리프(말단) 노드까지의 경로가 있는 경우 결정 트리가 유효하다고 할 수 있다. 그리고 모든 리프에 도달할 수 있는 경우 의사결정 트리는 prun(제거, 가지치기)된다. 즉 그 이상 트리를 확장하지 않는 다는 것이다. 그러므로 지금 문제의 모든 알고리즘에 해당하는 유효하고 제거(prun)된 결정 트리가 존재한다. 이에 대한 정리를 몇개 살펴보자.
보조 정리 1
이진 트리의 노드 수가 m이고, h가 이진 트리의 높이(깊이)이면 \(d\geq log_{2}{m}\)이다.
N을 높이 h의 완전 이진 트리의 노드 개수라고 하자. 그렇다면 \(N=1+2^2+...+2^h=(2^{d+1})-1\)이다. m을 유효하고 제거된 이진 결정 트리의 노드 개수라고 하자. 당연히 \(m\leq N\)일 것이다. 이를 통해 우리는 \(m\leq (2^{d+1})-1 \Rightarrow m<(2^{d+1})\Rightarrow log_{2}{m}<d+1\)와 같은 식을 얻을 수 있다.
보조 정리 2
k를 부등식 비교 노드(<, >)를 포함하는 이진 트리의 총 노드 수라고 하자. n개의 개별 키 중에서 키 x를 탐색하기 위한 유효하고 제거된 결정 트리가 되려면 비균등 노드의 수는 최소한 n(<=k)개의 노드여야 한다.
\(1\leq i \leq n\)에 대한 배열 S의 i번째 요소의 값을 \(S_{i}\)라고 하자. 그렇다면 모든 \(S_{i}\)는 최소한 하나의 비균등 노드에 포함되어야한다.
이제 이 보조 정리를 이용하여 새로운 정리를 증명해보자.
정리 1
모든 비교 기반 탐색 알고리즘은 최악의 경우 최소 \(\Omega(logn)\)번의 비교가 필요하다.
입력이 일련의 수들의 시퀀스라고 하자(a=[a1, a2, ..., an]). 이러한 각 알고리즘에는 유효한 제거된 이진 트리가 존재한다. N을 리프 노드의 총 개수, h를 이진 결정 트리의 높이라고 하자.
- N=n이다. 리프 노드의 수는 가능한 출력의 수와 관련이 있기 때문이다.
- \(N\leq 2^h\)이다. 각 레벨 i에는 \(2^i\)개의 노드가 있는데, 모든 리프 노드가 같은 높이에 위치하지 않기 때문이다.
- \(2^h \geq n\)이다. 1. 2.을 통해 알 수 있다.
- \(h \geq logn\)(h는 비교 횟수)이다.
모든 리프 노드는 루트 노드에서 도달해야 하므로 h는 루트 노드에서 리프 노드까지의 가장 긴 경로(h)에 있는 불균등 노드의 총 수를 나타내기 때문에 최악의 불균등 비교 수를 나타낸다.
The Selection Problem
Kth order Statistics
탐색 문제는 주어진 검색 키 x와 값이 정렬된 배열에 대해 x와 동일한 키를 가진 배열의 인덱스 k를 반환한다. 여기서 선택 문제란 검색 문제의 특수한 유형이다. 인덱스 k와 정렬되지 않은 배열이 주어졌을 때 해당하는 키 x를 찾는 것이다. 즉,
- k=1이면, 배열에서 가장 작은 키를 찾는다.
- k=n이면, 배열에서 가장 큰 키를 찾는다.
- k=n/2이면, 배열의 중앙값 키를 찾는다.
이말은 주어진 배열에서 k번째로 가장 작은 키를 찾는 방법이다. 두가지 방법을 생각해볼 수 있다.
- 방법 1: 정렬 알고리즘을 먼저 사용한 뒤 A[k]로 표시되는 k번째 인덱스에서 직접 k번째로 작은 요소를 찾을 수 있다.
- 병합 정렬 알고리즘을 사용한다고 했을 때, 배열을 정렬하는데 \(nlogn\) 비교를 수행하고 A[k]에 접근하는데는 \(O(1)\)의 시간복잡도를 가진다
- 방법 2: 다음에 있을 내용처럼 분할 정복 방법을 사용하여 Lomuto의 배열 분할 알고리즘(퀵 정렬, 참고)을 사용하여 시간 복잡도가 \(\theta(nlogn)\)보다 나은 알고리즘을 개발할 수 있다. 이를 빠른 선택 알고리즘이라고 한다.
The Quick Select Algorithm

빠른 선택 알고리즘은 Loumuto의 배열 분할 알고리즘을 사용하기 때문에 빠른 정렬 알고리즘과 유사하다. 배열 분할 알고리즘은 아래와 같이 분할 인덱스 s에서 피벗 값을 찾아 일부 피벗 요소(ex. 첫 번째 요소)를 중심으로 목록을 재정렬한다. 분할 후 왼쪽의 요소들은 피벗 요소보다 작고 오른쪽의 요소들은 피벗 요소보다 크다. 첫 번째 요소를 피벗으로 하였다면 p=A[0]이었는데, 분할이 이뤄지면 p=A[s]가 되는 것이다. 수도 코드로 살펴보자.
//Top-level call: kth smallest = Selection(1, n, k);
keytype selection(index low, index high, index k){
//input: Array S with n elements and positive integers n and k(k<=n)
//output: the kth smallest keys in Array S
index pivotpoint;
if(low == high), then return S[low];
else{
partitioning(low, high, &pivotpoint);
if(k == pivotpoint), then return S[pivotpoint]
else if(k < pivotpoint), then Selection(low, pivotpoint-1, k)
else, Selection(pivotpoint+1, high, k);
}
}다음 코드는 피벗을 배열의 첫번째 요소로 선정했을 때이다. 우선 'low == high'라는 것은 배열의 크기가 1일 때이므로 그냥 S[low]를 반환하면 된다. 이외의 경우에는 우선 파티셔닝을 한번 수행한다. 그렇다면 피벗을 기준으로 왼쪽은 피벗보다 작고, 오른쪽은 피벗보다 큰 수들이 위치한다. 만약 k와 지금 피벗이 같다면 S[pivotpoint]를 반환하면 된다.
만약 그렇지 않다면 k가 현재 피벗보다 큰지 적은지 판단한 다음에 피벗 기준 왼쪽 부분배열에서 다시 Selection()을 하거나, 오른쪽 부분배열에서 다시 Selection()을 하면 된다. Lomuto partitioning에 해당하는 수도 코드도 다시 확인해보자.
void partition(index low, index high, index &pivot){
keytype pivotitem = S[low];
index j = low;
index i;
for(i=low+1; i<=high; i++){
if(S[i] < pivotitem){
j++;
exchange S[i] and S[j];
}
}
pivotIndex = j; //put pivotitem at pivotpoint
exchange S[low] and S[pivotpoint];
}Lomuto 파티셔닝같은 경우는 이전 분할 정복에서 다루었으니 설명을 생략하겠다.
Impact of pivot of on the time complexity of Select Algorithm
그럼 선택 알고리즘을 이용한 방법의 시간 복잡도를 알아보자. 위에서 알 수 있듯이, 선택 알고리즘의 실행 시간은 입력 배열을 분할하는데 소요되는 시간에 의해 좌우된다. 분할 이후 피벗이 배열의 가운데에 위치할 수록 알고리즘이 빠를 것이고 피벗이 불균등하게 배치될수록 느릴 것이다.
- worst-case 시간 복잡도: 퀵 정렬과 유사하게 입력 배열이 이미 오름차순으로 정렬되어 있고 k=n일 때이다. \(T_{w}(n)=\theta(n^2)\).
- best-case 시간 복잡도: 분할이 최적으로 이뤄졌을 때이다. \(T_{b}(n)=\theta(logn)\).
average-case 시간 복잡도
평균 시간 복잡도는 당연히 알아내는게 더 복잡할 것이다. 평균 시간 복잡도는 입력 배열의 특정 값이 아니라 입력 배열의 상대적 순서에 따라 결정된다. 따라서 우리는 다양한 입력 중에 어떤 입력을 얼마나 자주 접할 것으로 예상하는지 가정해야한다. 배열의 요소 개수가 n이라면 n!개의 고유한 입력이 존재하고 각 입력이 들어올 가능성이 동일하다고 가정하자. 우리가 selection()을 실행할 때 분할 인덱스는 각 입력 배열에 대한 재귀 호출마다 동일하지 않다. 분할이 이뤄질 때 일부는 균형을 이룰 수 있고 일부는 불균형할 수 도 있는 것이다.
균형 및 불균형 분할의 혼합이 재귀 호출 트리에서 무작위로 배포될 것이다. 따라서 우리는 중앙값 피벗을 사용하여 더 나은 효율성을 얻을 수 있다. 이전처럼 배열의 첫번째 요소가 이닌, 난수 생성기를 사용하여 피벗 인덱스를 선택하면 다음 내용처럼 더 나은 효율성을 얻을 수 있다.
Top-level call: kthSmallest = Selection(1, n, k);
keytype Selection3(index low, index high, index k){ // probabilistic version
index pivotpoint;
if (low == high ), then return S[low];
else{
partition3(low,high,pivotpoint); // see next slide
if (k = =pivotpoint), then return S[pivotpoint]
else if (k<pivotpoint),then Selection3(low,pivotpoint-1,k)
else, then Selection3(pivotpoin+1,high, k)
}
}
void Partition3(index low, index high, index &pivotpointx ){
// return an index between low and high inclusive with equal probability
// using random Number Generator (RNG) function.
index randspot = RNG (low, high); // low <= Randspot <= high
keytype pivotitem = S[randspot];
index j = low;
for(index i = low +1; i high ; i++){
if ( S[i] < pivotitem ){
j++;
exchange S[i] and S[j];
}
}
pivotpoint = j;
exchange S[low] and S[pivotpoint]; // put pivotitem at pivotpoint.
}Deterministic Algorithm vs. Probabilistic Algorithm
그럼 두가지 알고리즘의 평균 시간 복잡도를 비교해보자. 두가지 사례를 예시로 들어보자.
첫번째 사례는 가증한 모든 입력 인스턴스의 분포에 대한 합리적인 가정이 있는 경우이다. 이때는 probability weighted average method를 사용하여 가능한 모든 입력 인스턴스에 대한 알고리즘의 average-case 시간 복잡도를 계산할 수 있다. 만약에 알고리즘의 입력 배열에 n개의 요소가 있을 때 n!개의 가능 인스턴스 수가 있는데 각 n!개의 순열은 동일한 확률을 갖는다고 생각해보자.
두번째 사례는 입력 인스턴스에 대한 합리적인 분포를 설명할 수 없을 때이다. 당연히 이때는 확률 분석을 사용할 수 없다. 이 경우에는 결정론적 알고리즘의 일부를 랜덤으로 변경함으로써 결정론적 알고리즘을 확률적 알고리즘으로 변환할 수 있다. 예를 들어 난수 생성기 함수 random(low, high)를 사용하여 모든 입력에 대해 평균 시간 복잡도를 얻기 위해 결정록적 빠른 선택 알고리즘에 무작위화를 추가할 수 있다.
case 1
첫번째 사례는 알고리즘이 동일한 특정 입력 인스턴스에서 여러번 실행되는 경우 키 비교의 수는 항상 동일하다. 그리고 다른 입력 인스턴스의 경우 키 비교의 수는 입력 배열의 특정 값이 아니라 입력 배열의 값의 상대적 순서에 의존하기 때문에 다르다. 예를 들어 [1, 2, 3, 4, 5, 6]와 [3, 2, 1, 6, 4, 5]의 속도는 서로 다를 것이다.
case 2
두번째 사례는 난수 생성기 함수를 이용하기 때문에 임의의 알고리즘이 동일한 특정 입력 인스턴스에서 여러번 실행되는 경우에 키 비교의 수는 알고리즘을 실행할 때마다 다르다.
매번 동일한 입력에서 무작위 알고리즘을 실행하고 속도는 무작위 선택에 따라 달라지며 속도는 이전 속도와 다를 가능성이 더 크다. 그리고 임의의 작업이 입력 순서를 무관하게 만들기 때문에 특정 입력 인스턴스가 worst-case operation을 생성하지 않는다. 또한 이 사례에서는 입력 인스턴스에 대한 특정 분포를 가정하지 않는다.
특정 입력에 대해 균일 분포를 사용하여 무작위로 피벗을 선택하면 균형적인 분할을 얻을 확률이 높다. 이는 전체 입력의 평균을 낼 때 비교 횟수가 선형임을 의미한다. 따라서 피벗이 균일 분포에 따라 무작위로 선택될 때 특정 입력에 대한 키 비교 횟수의 예상 값은 선형 \(\theta(n)\)가 된다.
자료 출처
- Introduction to The Design and Analysis of Algorithms / Ananu Levitin
- FOUNDATIONS OF ALGORITHMS / RICHARD E. NEAPORITAN
'알고리즘 > 수업 복습' 카테고리의 다른 글
| An Introduction to Theory of NP and Intractability (0) | 2021.12.22 |
|---|---|
| Introduction to Computational Complexity theory of a Problem: The sorting Algorithm Problem (0) | 2021.12.13 |
| Branch and Bound Method (분기 한정법) (0) | 2021.11.30 |
| Backtracking Algorithm Design Method (백트래킹 알고리즘) (1) | 2021.11.22 |
| Greedy Algorithm Design Pattern 2(탐욕 알고리즘) (0) | 2021.11.08 |




댓글