이전까지는 주어진 문제를 해결하는 알고리즘 분석에 중점을 뒀었다. 즉 문제 자체의 속성보다는 특정 알고리즘의 속성에 초점을 맟췄었다. 예를 들어 순차 탐색 알고리즘의 시간 복잡도를 분석할 때 시간 복잡도는 \(\theta(n)\)이다. 이것은 당연히 탐색 문제에 \(\theta(n)\) 알고리즘이 필요하다는 의미가 아니다. \(T(n)=n\) 함수는 탐색 문제의 속성이 아닌 문제에 대한 탐색 알고리즘의 속성이다.
이 장에서는 계산 복잡도 이론(computational complexity theory)이라는 이론적인 컴퓨터 과학 분야에 대해 알아볼 것이다. 알고리즘 분석에서는 문제를 해결하기 위해 특정 알고리즘이 필요로 하는 리소스 양을 분석하는데 전념했지만 계산 복잡성 이론은 동일한 문제를 해결하는데 사용할 수 있는 모든 가능한 알고리즘에 대해 보다 일반적인 질문을 던진다.
계산의 수학적 모델을 사용하여 계산 문제(컴퓨터가 해결하는 작업)를 해결하는데 필요한 시간이나 메모리의 양을 수량화 한다. 그리고 계산 복잡도 이론은 주어진 문제를 해결할 수 있는 모든 가능한 알고리즘의 시간 효율성에 대한 하한(한계)를 결정하려고 한다.
계산 복잡도 이론에서는 주어진 제한된 자원으로 해결할 수 있거나 해결할 수 없는 문제를 분류하려고 한다. 사용 가능한 자원에 대한 제한을 부과하는 것은 계산 복잡성 이론과 계산 가능성 이론을 구별하는 것인데 계산 가능성 이론은 어떤 종류의 문제를 알고리즘적으로 해결할 수 있는지 묻는다.
A Lower and Upper Bounds of a Computational Problem
문제의 시간 복잡도에 대한 상한 T(n)을 표시하려면 실행 시간이 최대 T(n)인 특정 알고리즘이 있다는 것만 보여주면 됐었다. 하지만 하한을 증명하는 것은 훨씬 더 어렵다. 하한은 주어진 문제를 해결하는 모든 알고리즘에 대해 설명하기 때문이다. "가능한 모든 알고리즘"이라는 문구는 현재 알려진 알고리즘뿐만 아닌 미래에 발견될 수 있는 모든 알고리즘을 포함한다. 문제에 대한 T(n)의 하한을 표시하려면 어떤 알고리즘도 T(n)보다 낮은 시간 복잡도를 가질 수 없음을 보여야 한다.
예를 들어 퀵 정렬의 worst-case 시간 복잡도는 \(T(n)=\theta(n^2)\)이었다. 컴퓨터 과학자들은 해당 시간복잡도를 가지는 정렬 알고리즘에 만족하지 않았기 때문에 \(T(n)=\theta(nlogn)\)인 병합 정렬 알고리즘이라는 효율적인 알고리즘을 개발하였다. 10억 개의 요소가 있는 배열의 경우 오프라인 어플리케이션에서는 병합 정렬의 지연이 허용되지만 온라인 어플리케이션에서는 이러한 지연이 허용되지 않는다고 할 때, 키 비교 연산만을 기본 연산으로 사용하는 온라인 어플리케이션을 위한 새로운 효율적인 선형 시간 복잡도를 가지는 정렬 알고리즘을 개발할 수 있을까? 이에 대한 답은 우선 NO이다.
문제가 주어졌을 때, 우리는 다음 중 하나를 수행할 수 있다.
- 문제에 대한 보다 효율적인 알고리즘을 개발하기 위해 노력한다.
- 보다 효율적인 알고리즘 개발이 불가능하다는 것을 증명하려고 한다
정렬 연산 문제의 경우 키 비교 연산만을 기본 연산으로 하여 병합 정렬보다 우수한 새로운 정렬 알고리즘을 개발하는 것은 불가능함이 증명되었다.
따라서 주어진 계산 문제에 대해 기존 알고리즘 보다 더 나은 알고리즘을 개발(1.)하기 전에 우리는 계산 문제 자체의 이론적 하한을 알아야 한다. 그리고 계산 문제의 기존 알고리즘의 최악의 시간 복잡도와 계산 문제의 이론적 하한을 비교해야 한다. 기존 알고리즘의 worst-case 시간 복잡도가 문제의 이론적인 하한값보다 크면 새롭고 효율적인 알고리즘을 개발하기 위해 노력할 수 있는 것이다. 그게 아니라면 새로운 알고리즘을 개발할 필요는 없다.
정리해보자면 주어진 계산 문제의 하한은 주어진 계산 문제의 알고리즘의 최악의 시간 복잡도에 대한 하한이다. 모든 알고리즘은 과거에 개발된 알고리즘과 미래에 개발될 수 있는 모든 알려지지 않은 알고리즘을 의미한다. 주어진 문제는 문제의 하한과 동일한 효율성을 갖는 경우 tight lower bound를 갖는다. 하한의 몇가지 예시는 fig 1에서 확인할 수 있다.
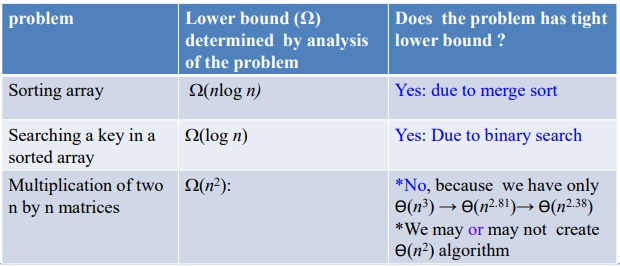
n*n 크기의 행렬 2개의 곱을 수행하는 문제의 경우 알고리즘 설계 방법론을 사용하여 이 문제에 대해 2차 시간 복잡도를 갖는 알고리즘을 찾는 노력을 계속할 수 있다. 아마도 미래에는 \(\theta(n^{2.38})\)보다 더 나은 시간 복잡도를 가지는 알고리즘을 개발할 수도 있을 것이다. 그러므로 주어진 문제에 대한 목표는 이론적 하한 \(\Omega(f(n))\)을 결정하고 문제에 대한 \(\theta(f(n))\)알고리즘을 개발하는 것이다.
Lower Bound for Sorting only by Key Comparison
정렬 알고리즘은 두 가지 유형의 그룹으로 나눠 볼 수 있다.
- Group 1: 키 비교 및 복사 작업만 사용하는 정렬 알고리즘. 이외의 다른 작업은 할 수 없다. 예시로는 선택/버블/삽입/퀵/힙/병합 정렬이 있다.
- Group 2: 키 비교 및 복사 작업 외에도 다른 작업을 사용하는 정렬 알고리즘. 이러한 알고리즘은 키에 대한 산술 연산을 수행할 수 있고, 키를 배열의 인덱스로 사용할 수도 있다. 예시로는 버킷/카운팅/기수 정렬이 있다.
Group 1의 알고리즘 대부분은 이전에 다뤄본적이 있어서 익숙할 것이다. 이들의 worst-case 시간 복잡도에 대해 정리하면 fig 2와 같다.
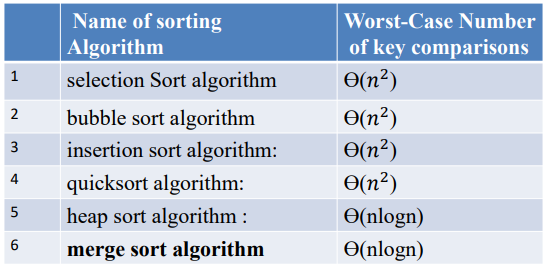
키 비교만을 사용하여 \(\theta(nlogn)\)보다 나은 시간 복잡도를 가지는 더 좋은 정렬 알고리즘을 개발할 수 있을까? 이에 대한 답은 위에서도 말했듯이 NO이다. 정렬 문제의 하한은 병합 정렬 알고리즘의 시간 복잡도와 동일하기 때문이다.
Binary Decision Tree
키 비교를 기반으로 하는 결정은 이진 결정 트리의 분기를 이용해 모델링 할 수 있다. 예를 들어 3개의 key들을 정렬하는 알고리즘을 살펴보자.
void sortthreeKeys(keytype S[]){
a = S[1]; b = S[2]; c = S[3]; //initialization
if(a < b)
if(b < c), then S = a, b, c;
else if(a < c), then S = a, c, b;
else, S = c, a ,b;
else if(b < c)
if(a < c), then S = b, a, c;
else, S = b, c, a;
else
S = c, b, a;
}
fig 3는 해당 수도 코드에 대한 이진 결정 트리이다. 특정 입력 인스턴스의 경우 알고리즘의 동작은 루트노드에서 말단노드까지의 고유한 경로를 따른다. 여기서 가능한 입력 인스턴스의 수는 6(3!)이다. 이번에는 3개의 key 값들을 서로 교환하면서 정렬하는 알고리즘을 알아보고 이를 이진 결정 트리로 표현해보자.
void exchange_sort(int n, keytype S[]){
for(i=1; i<=n; j++)
for(j=i+1; j<=n; j++)
if(S[i] < S[j])
exchange S[i] and S[j]
}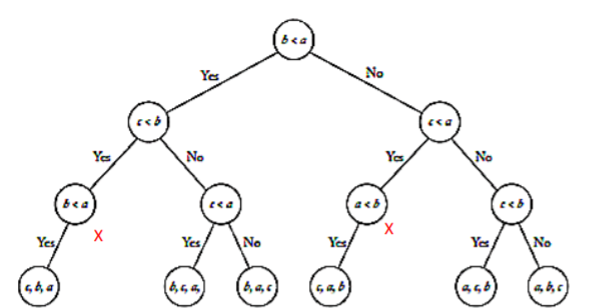
여기서도 특정 입력 인스턴스의 경우 알고리즘의 동작은 루트 노드에서 말단 노드까지 고유한 특정 경로를 따르는 것을 볼 수 있다.
Generalization
이제 위에서 알아봤던 것들을 일반화 시켜보자. 입력은 크기 n의 숫자가 담긴 배열이다(\(a = [a_1, a_2, ..., a_n]\)). 모든 간선은 "<" 또는 ">"라는 레이블을 가진다. 때문에 입력 배열들의 요소가 모두 구별된다고 가정한다. 말단 노드의 레이블은 출력할 값이다. 이는 정렬된 숫자들의 시퀀스이다. 이 모델의 실행은 루트 노드에서 시작된다. 그리고 내부 노드에서 (i:j)라는 레이블이 있는데 비교연산 \(a_i<a_j\)가 이뤄진다. 그러므로 왼쪽 하위 트리에서는 \(a_i<a_j\)를 감지하고 오른쪽 하위 트리에서는 \(a_i>a_j\)를 감지한다.
해당 모델의 실행 흐름은 비교 결과에 따라 적절한 레이블이 있는 분기를 따른다. 따라서 이진 결정 트리는 정렬 문제를 모델링할 수 있으며 정렬 알고리즘의 실행은 루트에서 말단 노드까지의 경로에 해당한다. 크기 n의 특정 입력 인스턴스에서 가능한 출력의 수는 n!이고 가능한 입력의 총 개수또한 n!이다. 올바른 정렬 알고리즘은 입력 시퀀스의 각 순열을 생성해야 하므로 비교 정렬이 정확하기 위한 필수 조건은 n개의 요소가 있는 각 순열이 하나의 말단 노드에 나타나야 하고 각 말단 노드들은 루트로부터 도달할 수 있어야 한다는 것이다.
위의 내용을 바탕으로 위의 "비교 정렬 알고리즘의 이진 결정 트리는 언제 유효한가?'라는 질문의 답에 대해 생각해보자. 비교 기반 정렬 알고리즘의 해당 이진 결정 트리는 루트 노드에서 입력에 대해 가능한 순열을 정렬하는 말단 노드까지의 경로가 있는 경우에 유효하다. 즉, 크기가 n인 모든 입력 인스턴스를 정렬할 수 있다. 따라서 n개의 키를 정렬하기 위한 모든 결정론적(예측한대로 동작) 알고리즘에는 적어도 하나의 유효한 해당 이진 결정 트리가 있다.
주어진 입력 인스턴스에 대해 결정 트리에서 수행된 비교 횟수는 주어진 입력에 대해 따라가는 경로에 있는 내부 노드들의 수와 동일하다. 이것은 내부 노드의 수와 경로의 길이가 같다는 것을 의미한다. 따라서 결정 트리가 수행하는 최악의 비교횟수는 트리의 깊이인 말단까지의 가장 긴 경로의 길이다. 이에 관한 두가지 정리를 알아보자.
- 정리1: key 비교로만 n개의 고유한 key들을 정렬하는 결정론적 알고리즘은 최악의 경우 최소 \(log(n!)\)번의 비교를 수행해야 한다. 이것은 '# of Comparison >= log (n!)'을 의미한다.
- 정리2: 모든 비교 기반 정렬 알고리즘에는 최악의 경우 적어도 \(\Omega(n*logn)\)의 비교가 필요하다. 이는 '# of comparison >= nlogn'임을 의미한다.
정리에 대한 증명은 생략하겠다.
Summary
- 비교 기반 결정은 트리의 분기로 모델링될 수 있다. 즉, 레코드 간의 비교를 기반으로 하는 정렬 알고리즘은 노드가 비교에 해당하고 분기가 가능한 결과에 해당하는 이진 트리로 볼 수 있다.
- 결과 트리의 최소 말단 노드 수는 n!으로 표시된다.
- n!개의 말단 노드가 있는 트리의 최소 깊이는 \(\Omega(n*logn)\)으로 표시된다.
자료 출처
- Introduction to The Design and Analysis of Algorithms / Ananu Levitin
- FOUNDATIONS OF ALGORITHMS / RICHARD E. NEAPORITAN
'알고리즘 > 수업 복습' 카테고리의 다른 글
| An Introduction to Theory of NP and Intractability (0) | 2021.12.22 |
|---|---|
| More Computational Complexity theory of a problem :The searching Algorithm (0) | 2021.12.21 |
| Branch and Bound Method (분기 한정법) (0) | 2021.11.30 |
| Backtracking Algorithm Design Method (백트래킹 알고리즘) (1) | 2021.11.22 |
| Greedy Algorithm Design Pattern 2(탐욕 알고리즘) (0) | 2021.11.08 |




댓글