분할 정복(DC로 줄이겠음)에 이어서 이번에는 Dynamic Programming(동적 계획법, DP로 줄이겠음)이라는 디자인 패턴에 대해 알아보자.
Introduction to Dynamic Programming
제목에 DP에 대한 해석을 '프로그래밍'이 아닌 '계획'으로 했다. 즉 DP의 Programming은 컴퓨터 프로그래밍이 아닌 계획을 의미한다. 원래 DP는 다단계의 의사결정을 최적화하기 위한 방법이었는데, 현재는 최적화 기법의 특정 유형으로 제한되는 일반적인 알고리즘 설계 기법이다.
말이 좀 어려운것 같다. 다르게 설명하자면 DP는 중복되거나 종속적인 하위 문제로 문제를 해결하기 위한 기술이다. 일반적으로, recurrence relation에서 하위 문제가 발생한다. 이 방법은 중복되는 하위 문제를 반복적으로 해결하는 대신 한 번 해결한 결과를 표에 기록하고 필요할 때 표에서 찾는다. 즉 동적 알고리즘이 재연산을 하는 대신에 테이블을 조회한다.
이런 설명을 들었을 때 '분할 정복이랑 비슷한거 아닌가?'라는 생각이 들었다. 어쨌든 여기서 확인할 수 있는 차이점은 분할 정복과 달리 DP에서는 해결한 sub problem의 결과를 table에 따로 저장해 놓는다는 것이다. 예시를 보고 차이를 생각해보자.
Generating Fibonacci Number using DP
피보나치 수열에 대해 간단히 설명하자면 '첫째항과 둘째항이 1이며 그 뒤의 모든 항은 바로 앞 두항의 합인 수열'이다. '1, 1, 2, 3, 5, 8, ...' 이런식이다. 일단 현재는 DP보다는 분할 정복이 익숙하니 한번 재귀관계를 정의해보자.
- 피보나치 수열의 n번째 항을 'F(n)'이라고 하자.
- 그렇다면 우리는 관계식 'F(n) = F(n-2) + F(n-1), F(0)=1, F(1)=1'을 정의할 수 있다.
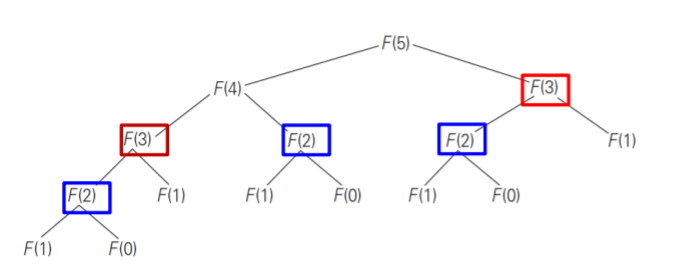
재귀 과정을 fig 1처럼 나타낼 수 있는데 F(2)나 F(3)를 필요할 때 마다 계산하게 된다. 이제 이를 수도 코드로 표현해보면

다음과 같이 표현할 수 있다. 시간 복잡도는 이전에 배운 방법으로는 구하기 힘드니 저렇게 나온다고 알고만 있자. 그런데 저번 게시글에서 "재귀 알고리즘을 이용하여 문제를 해결할 수 있게되면 이후 iterative version을 작성하여 효율적인 알고리즘을 작성한다(iterative algorithm이 효율성이 더 좋다)."라고 언급을 했었다. 여기서도 이를 적용해보자.

반복문으로 고친 버전이다. 반복문을 하나씩 돌 때마다 배열 F에 새로운 피보나치 수가 저장된다. 위의 recursive 버전에서는 F(n)을 구하기 위해 F(n-1)과 F(n-2)를 새롭게 구해줘야 했다. 하지만 iterative 버전에서는 F(n)을 구하려면 이미 배열에 저장되어 있는 F(n-1)과 F(n-2)를 가져오면 된다. 시간 복잡도도 계산하기 쉽다. 반복문에서 i를 n이 될 때까지 1씩 증가시키므로 반복횟수를 쉽게 파악할 수 있다.
Main steps of DP
이제 DP에 대한 감이 오는지 모르겠다. 본인은 아직도 아리송하다. DP의 주요 순서를 알아보며 더 명확하게 이해해보자.
- larger instance problem에 대한 해결책과 smaller instance problem에 대한 해결책에 대한 반복을 설정
- smaller instance problem을 해결하고 해당 결과를 테이블에 기록
- 동일한 sub-problem이 다시 발생할 경우 테이블에서 해당 문제의 해결책을 추출
Divide & conquer Vs DP
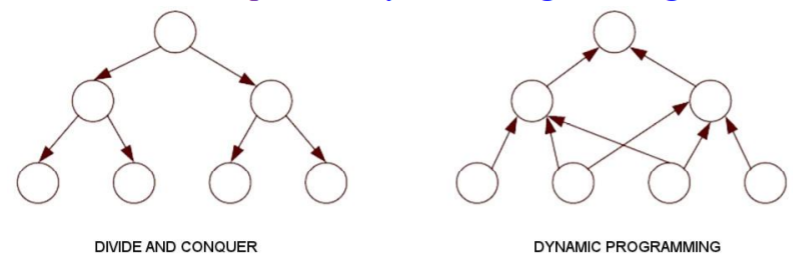
아까부터 계속 헷갈렸던 두 디자인 패턴의 차이를 확실히 해보자. 우선 DC는 주어진 문제를 독립적인 하위 문제로 분할하고 각 문제를 무작정(계획 없이)해결한다. 때문에 문제들을 재귀적으로 해결하고 공통된 subproblems을 반복해서 해결한다. 물론 병합 정렬같이 sub problems가 중복되지 않는 경우도 존재하긴 한다.
DP는 주어진 문제를 일부 값을 공유하고 계획 있게 해결하는 종속적인 subproblems으로 분할한다. 때문에 모든 subproblems를 한 번만 해결한 후 테이블에 결과를 저장하고 해당 문제가 다시 발생하면 이를 검색한다.
DC는 부분 문제들이 독립적이고, DP는 부분 문제들이 종속적임을 기억하자. 그렇기 때문에 DP는 최적의 원리를 만족하는 경우에만 적용할 수 있다는 제한점이 있다. 문제의 한 instance에 대한 최적의 해결책이 모든 하위 문제에 대한 해결책을 항상 포함하고 있는 경우에 최적성 원칙을 만족시킨다고 한다.
Step of DP
DP 알고리즘을 개발하기 위해서는 두 단계를 필요로 한다.
- 문제의 인스턴스에 해결책을 제공하는 재귀적 성질을 알아낸다.
- 작은 문제를 먼저 해결함으로써 문제의 인스턴스를 상향식으로 해결한다.
Compute Binomial Coefficient using DP
DP를 이용하여 이항 계수를 구해보자. 나한테는 조합이라는 표현이 더 익숙하다.
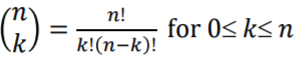
참고로 조합의 성질 중에 k를 n-k로 바꿔도 결과는 동일하다라는 특징이 있음을 기억하자. 그리고 다른 성질로는
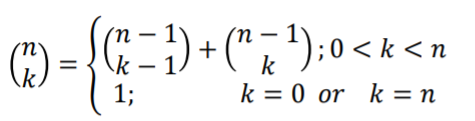
다음과 같은 성질이 존재한다. 이것을 보고 우리는 바로 재귀 관계를 설정할 수 있다. 그리고 n, k라는 두개의 변수에 따라 결과값이 결정되므로 문제들을 저장하기 위해 2차원 테이블을 사용해야 함을 짐작할 수 있다. 결과값이 저장되면

다음과 같이 저장될 것이다. 해당 테이블을 이용하여 우리는 B[n][k]를 계산할 수 있게된다.
수도코드를 확인해볼건데 우선 recursive version부터 확인해보자.

코드자체는 매우 간결하다(bin->binR로 수정). DC는 각각의 작은 인스턴스가 두번이상 계산되도록 하향식으로 무작정 계산한다. n!과 k!를 재귀로 계산해야하므로 딱 보기에도 비효율적인 느낌이 든다. 반면에 DP를 적용한 iterative version은 어떨까?

DP 알고리즘은 각 인스턴스를 한 번만 수행하도록 아래에서 위로 순서대로 해결하여 재귀를 반복으로 변환한다.
Time complexity for Binomial Coefficient using DP
시간 복잡도를 계산해보자. fig 7을 보면 두개의 반복문이 존재한다. 그러므로 총 반복횟수는 바깥 반복문의 반복횟수와 안쪽 반복문의 반복횟수의 곱이다. 그리고 baisc operation(addition)은 반복문 내부에 위치한다. 각 반복문의 반복횟수를 표로 정리하면 다음과 같다.

inner loop에서 (k+1)번 반복이 n-k+1번 있다는 것에 주의하자. basic operation의 횟수를 \(A(n,k)\)라고 한다면, \(A(n,k)=(1+2+3+4+...+k)+{(k+1)+(k+1)+...+(k+1)} = \frac{k(k+1)}{2}+(n-k+1)(k+1) = \frac{(2n-k+2)(k+1)}{2}\)이다. 그러므로 \(A(n,k) \in \theta(nk)\)
Floyd's Algorithm (DP) for graph problem
이번에는 조금 복잡한 problem을 해결해보자. 해당 problem은 어떤 여행자가 한 도시에서 다른 도시로 가야하는데 직항편이 없을 때, 환승을 통한 최단 경로를 찾는 것이다. 해당 문제를 컴퓨터에게 인지시키려면 어떻게 해야할까?

여기서 새로운 자료구조인 그래프(처음 듣는다면 간단한 정의는 찾아보자. 금방 이해할 수 있다)를 사용할 수 있다. 그리고 여행자가 어느 도시로 간다고하는 방향이 존재하므로 그래프 중에서도 유향 그래프를 활용하면 될 것이다. 각 정점은 도시, 각 간선은 거리로 표현한다. 이를 통해 몇 가지를 정의할 수 있다.
- Def 1: 경로는 그래프 내 인접한 정점들의 순서이다.
- Def 2: 단순 경로는 구별되는 정점을 가진 경로로, 동일한 정점을 두번 지나지 않는다.
- Def 3: 순환 경로는 마지막 정점이 첫 번째 정점에 인접한 단순 경로이다.
- Def 4: 경로의 길이는 경로의 가중치의 합계이다.
주어진 문제에 대해 다시 말하자면, 정점에서 다른 정점으로 가는 최단 경로를 찾아야 한다. 이를 위한 많은 방법이 존재한다. 그리고 당연하지만 그렇게 찾아낸 경로는 단순 경로이다. 하지만 한 정점에서 다른 정점으로의 단순 경로는 두개 이상일 수 있고 각 후보들은 이에 해당하는 길이를 갖는다. 따라서 이 길이들 중 최솟값을 갖는 경로를 찾아야하는 것이다. Floyd는 짧은 경로의 길이를 계산하고 최단 경로를 구성하는 알고리즘을 개발한다.
이 알고리즘은 각 정점에서 그래프의 다른 모든 정점까지의 최단 경로의 길이를 찾아 주어진 그래프의 최단 경로를 모두 계산한다. Floyd 알고리즘은 다음과 같이 거리 행렬의 수(n+1)를 연속적으로 계산하여 최단 경로를 기록한다.
\(D^{(0)}[i][j] \rightarrow D^{(1)}[i][j] \rightarrow D^{(k)}[i][j] \rightarrow D^{(n)}[i][j]\)
- 정점은 1에서 n까지 인덱싱: \(v_{1}, v_{2}, ..., v_{n}\)
- \(D^{(0)}[i][j]\): 이때 i와 j 사이에는 중간 정점이 없다. 따라서 graph의 인접 가중 행렬이다.
- \(D^{(1)}[i][j]\): 중간 정점으로 \(v_{1}\)만 사용하는 최단 경로의 길이
- \(D^{(2)}[i][j]\): i와 j사이의 중간 정점으로 집합\(\{v_{1}, v_{2}\}\)내의 정점들만 사용
- \(D^{(3)}[i][j]\): i와 j사이의 중간 정점으로 집합\(\{v_{1}, v_{2}, v_{3}\}\)내의 정점들만 사용
- 그러므로 \(D^{(k)}[i][j]\)는 중간 정점으로 집합\(\{v_{1}, v_{2}, v_{3}, ...,v_{k}\}\)의 정점만을 사용하는 정점 i에서 정점 j까지의 모든 경로 중 최단 경로의 길이와 같다.
- \(D^{(n)}[i][j]\)는 n개의 모든 정점을 중간 정점으로 하는 정점 i에서 정점 j로 가는 모든 경로 중 최단 경로를 의미한다. 즉 problem의 solution이다.
Step of DP 적용
위의 내용을 통해 초기 상태(\(D^{(0)}[i][j]\))를 정의할 수 있고, 어떤 재귀 관계를 가지는지도 알 수 있을 것 같다.
- \(D^{(k-1)}\)를 통해 \(D^{(k)}\)를 찾는 재귀관계를 설정한다. \(v_{1}\)에서 \(v_{k-1}\)까지를 중간 정점으로 하는 최단경로와 \(v_{k}\)를 중간 정점으로 꼭 거칠 때의 최단경로를 비교하여 더 작은 값을 \(D^{(k)}[i][j]\)로 설정하면 된다.
- \(D^{(k)}[i][j]=min\{D^{(k-1)}[i][j], D^{(k-1)}[i][k]+D^{(k-1)}[k][j]\}\)
- k=1에서 k=n까지의 상향식 접근을 이용하여 문제의 인스턴스를 해결한다.
Simple Example
간단한 인스턴스를 통해 이해해보자.
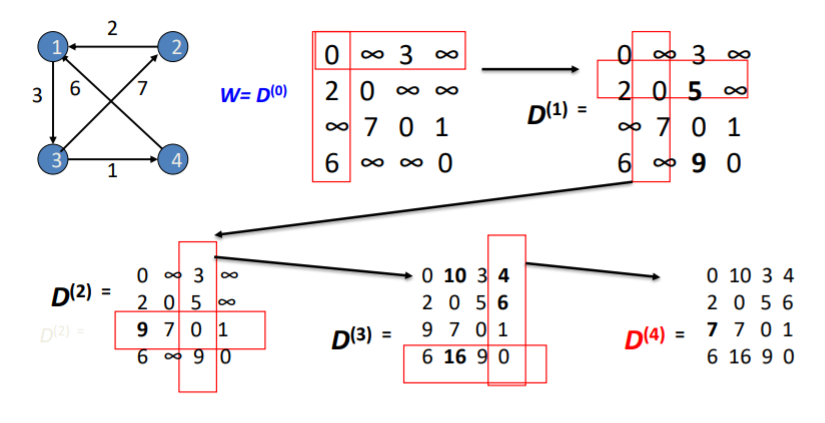
\(D^{(0)}\)일 때는 각 정점과 인접한 그래프들간의 거리를 나타냈다. 자기자신으로 가는 거리는 당연히 0이고, 간선으로 연결되지 않은 경우에는 자동으로 배제하기 위해 정점간 거리를 무한대로 설정해주었다. \(D^{(1)}\)일때는 중간 정점으로 1번 정점을, \(D^{(2)}\)일때는 1번, 2번 정점을, \(D^{(3)}\)일때는 1번, 2번, 3번 정점을, \(D^{(4)}\)일때는 1번, 2번, 3번, 4번 정점을 사용할 수 있을 때, i(행번호)에서 j(열번호)로 갔을 때의 최단거리이다.
Pseudo Code
수도코드로 표현해보자.

설명은 복잡했는데 코드로 표현해보니 굉장히 간단하다. 입력으로 \(D^{(0)}\)을 넣어주면 해당 알고리즘을 통해 i에서 j로 가는 최단거리를 알 수 있다.
시간 복잡도도 알기 쉽다. 1부터 n까지 반복하는 반복문 3개가 중첩되어 있으므로 \(T(n)=n*n*n\in \theta(n^3)\)이다. 그런데 뭔가 이상하다는 생각이 든다. 분명 해당 problem의 목적은 최단 거리가 아니라 최단 경로였다. 위의 알고리즘에서는 경로에 대한 정보는 저장하지 않았기에 최단 경로는 알 수가 없는 것이다.
Print Floyd's shortest path
우선 경로에 대한 정보를 저장하기 위해 P[i][j]라는 2차원 배열을 설정하자. 해당 인덱스안에는 i에서 j까지가는 최단경로에 있는 정점 중 가장 높은 인덱스를 갖는 정점의 인덱스가 들어있다. 이를 얻기 위해서 우리는 fig 10의 반복문을 다음과 같이 변경할 수 있다.
for(k=1; k<=n; k++)
for(i=1; i<=n; i++)
for(j=1; j<=n; j++)
if(D[i][k] + D[k][j] < D[i][j]){
P[i][j] = k;
D[i][j] = D[i][k] + D[k][j];
}이렇게 얻어낸 P를 통해 최단 경로상에 있는 중간 정점까지 알아내서 출력해보자. 이때의 입력으로는 P가 들어간다.

어떻게 최단경로를 알아내는건지 이해하기가 힘들다...😥 밑의 그림을 참고해보자.

P를 얻을 수 있게끔 fig 10을 개선하여 알고리즘을 돌리면 fig 12같은 결과를 얻을 수 있다. v5에서 v3까지의 최단 경로를 알아낸다고 해보자. fig 11에 5, 3을 넣어서 돌리면 path(v5, v3) => path(v5, v4) & path(v4, v3) => [path(v5, v1) & path(v1, v4)] & path(v4, v3)가 나온다. 여기에서는 DP가 아닌 DC를 적용했다. v5에서 v3까지의 최단 경로를 P[5][3]을 기준으로 둘로 쪼개고 또 각 부분을 P[i][j]값이 0이 나오기 전까지 잘게 쪼개는 것이다.
Summary: Steps to Solve Optimization Problem by DP
DP를 이용하여 최적화 문제를 해결할 때 우리는 3가지 단계를 따른다.
- 문제 발생 시 최적의 해결책을 제공하는 재귀적 성질을 확립
- 상향식으로 스칼라량의 최적 가치를 계산한다.
- 상향식으로 스칼라량의 최적값을 도출하는 데이터 항목(벡터량)의 순서를 구축한다
2단계와 3단계는 동시에 수행된다.
Optimal Binary Serach Tree using DP
About Binary Search Tree (BST)
이번에는 최적 이진 탐색 트리에 DP를 적용해보자. 이번에는 이진 탐색 트리라는 자료구조를 이용할 것이다. 이는 추로 dictionary 추상 자료형에 적용되는데 검색, 삽입 및 삭제 작업이 있는 요소의 집합이라고 보면된다. 다시 한번 이진 탐색 트리에 대해 정의하자면, 해당 트리에서 왼쪽 하위 트리의 모든 요소는 루트(root)요소보다 작고 오른 쪽 하위 트리의 모든 요소는 루트 요소보다 크다. (그래프와 동일하게 처음보는 자료구조라면 찾아보고 이해해햐함)
우선 트리를 이루는 노드(node)를 구현해야 한다. 노드는 어떤 값을 가지고 있고 또한 왼쪽, 오른쪽 하위노드를 가리키고 있어야한다. 대략 구현을 해보면
Struct nodeType{
KetType key;
nodeType* left;
nodeType* right;
}
Typedef nodeType* node_pointer;다음과 같이 정의할 수 있겠다. 그럼 특정 key k가 tree에 있는지 알아내기 위한 코드를 생각해보자.
void search(node_pointer tree, keytype keyin, node_pointer& p)
{
bool found;
p = tree;
found = false;
while(!found)
if(p->key == keyin)
found = true;
else if(keyin < p->key)
p = p->left;
else
p = p->right;
}이런식으로 구현할 수 있겠다. 그럼 key k가 주어졌을 때 비교횟수를 C(k)라고 하면 이것은 해당 key가 위치한 node의 깊이(루트부터 해당 노드사이의 간선 갯수)+1과 같다. 그렇다면 우리는 비교횟수 C(n)의 평균을 \(C_{ave}(n)=\sum_{i=1}^{n} c_{i}p_{i}\)라고 할 수 있다(\(p_{i}\)는 key가 i가 될 확률, \(c_{i}\)는 i를 탐색하는데 필요한 비교횟수).
Optimal Binary Search Tree
이제 최적 이진 탐색 트리를 살펴보자. 탐색 시, 어떤 key 값을 자주 탐색할 수록 해당 노드가 root에 가까이 위치하면 어떻게 될까? 당연히 비교 연산 횟수가 줄어들 것이고 이것은 탐색 시간을 감소시켜준다. 즉 이러한 이진 트리를 만드는 것이 이 파트의 Problem이다.
다시 문제를 구체적으로 정의해보자. n개의 고유 키가 저장된 정렬된 배열 A[1, ..., n]과 해당 키들이 검색될(검색 키) 확률이 담긴 배열 p[1, ..., n](A[1]부터 A[n]에 대응)이 주어졌을 때, 모든 검색 키의 평균 비교 개수가 가능한 작게끔 모든 키에 대한 이진 탐색 트리를 구성해야한다.
그렇다면 이를 위해 어떤 방법들을 생각해 볼 수 있을까? 우선 무식하게 접근해보자. C(n)을 node가 n개일 때 만들어 질 수 있는 BST의 개수라고 하자. 이때, \(C(n)=\frac{(2n)!}{(n!)(n!)(n+1)}, n>1, C(1)=1\)이다. 딱 봐도 n이 조금만 늘어도 수가 매우 커질 것 같다. 만약 n=4라면 우리는 14개의 고유한 BST가 있음을 알 수 있다. 이 14개의 트리들 모두를 비교하여 최적의 트리를 찾는 것은 오랜 시간이 걸릴것이다. 즉, 전체 탐색(Brute Force)기법을 적용했을 때는 시간 복잡도가 기하급수적으로 상승한다는 뜻이다.
그럼 다른 방법에는 무엇이 있을까? 지금 배우는걸 생각해보면 DP를 사용하는게 정답일 것이다. 모든 키가 검색될 확률이 동일하지 않은 것에 주목해보자.
- \(T_{1}\)을 \(a_{1}\)이 루트일 때의 최적 이진 트리라고 하자.
- \(T_{2}\)을 \(a_{2}\)이 루트일 때의 최적 이진 트리라고 하자.
- \(T_{k}\)을 \(a_{k}\)이 루트일 때의 최적 이진 트리라고 하자.
- \(T_{n}\)을 \(a_{n}\)이 루트일 때의 최적 이진 트리라고 하자.
- \(T_{k}\)에서, 각 루트가 아닌 키를 m이라고 하면, \(T_{k}\)에서 m을 찾는데 필요한 비교횟수는 m이 속한 하위 트리에서 m을 찾는 것보다 비교 연산이 한번 더 필요하다.
- 즉, \(T_{k}\)안의 키 m을 찾을 때, 한번의 비교는 평균 검색시간(\(Avg(n)\)에 1*\(p_{m}\)을 기여한다.
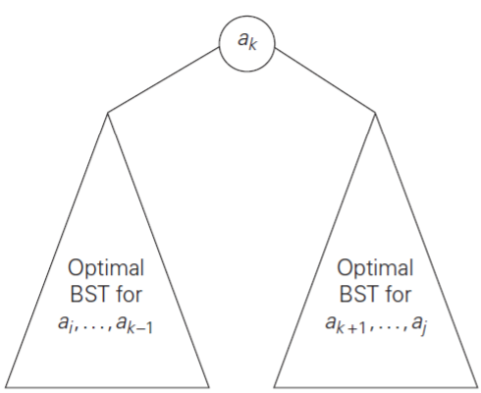
fig 14를 참고해보자. 그리고 i번째 키부터 j번째 key까지로의 최적 BST를 만들었을 때의 평균 검색 시간을 A[i][j]라고 하자. 그럼 \(T_{k}\)에서 평균 탐색 시간을 \(Avg(n)=A[1][k-1]+p_{1}+...+p_{k-1}+p_{k}+A[k+1][n]+p_{k+1}+...+p_{n}\)이라고 할 수 있다. 좀 더 설명을 보태자면, \(Avg(n)\)은 (왼쪽 하위 트리의 평균 시간) + (왼쪽 하위 트리의 루트와 비교하는 추가적인 시간) + (오른쪽 하위 트리의 평균 시간) + (오른쪽 하위 트리의 루트와 비교하는 추가적인 시간)이다. 더 간단하게 식으로 나타내자면 \(Avg(n)=A[1][k-1]+A[k+1][n]+\sum_{m=1}^{n}p_{m}\)이다. 그럼 하위 트리들이 모두 최적이라고 할 때 루트노드를 n번 바꿔볼 수 있고 그 중 하나가 최적 BST임을 알 수 있다.
- 즉 \(A[1][n]=min_{1\leq k\leq n}(A[1][k-1]+A[k+1][n])+\sum_{m=1}^{n}p_{m}\) (식 a)
\(\sum_{m=1}^{n}p_{m}\)은 루트 노드의 탐색시간이다. A[1][0] = 0이고, A[n+1][n] = 0이다.
이제 남은 문제는 루트 노드의 키값을 선택하기 위해 A를 어디에서 분할하느냐이다. {\(K_{1}, ..., K_{n}\)같은 집합이 주어지면 최적의 탐색시간을 얻기위해 어떤 순서로 이것들을 저장해야 하는가? 만약 중간 지점을 쪼갠다고해도 이것이 최적의 BST는 아니다. 우리는 (식 a)를 \(A[1][n]=min_{i\leq k\leq j}(A[i][k-1]+A[k+1][j])+\sum_{m=i}^{j}p_{m}, (i<j)\)로 일반화 할 수 있다. 이를 통해 2차원 배열 A를 채워나가면서 A[1][n]의 값을 얻으면 된다.
배열 A를 통해 최적값을 구할 수는 있지만 최적 BST의 모양을 알 수는 없다. 때문에 R이라는 2차원 배열을 하나 더 만든다. R의 각 칸에는 A배열에 최적값을 넣는 순간의 k값으로, 이는 i번째 키부터 j번째 key까지를 이용해 BST를 만들 때 루트가 되는 노드의 번호이다. 만약 루트가 된 node가 k라면, 왼쪽 하위트리의 루트는 R[1][k-1], 오른쪽 하위트리의 루트는 R[k+1][n]이 되는 것이다. 이렇듯 R을 이용해 재귀함수를 호출해주면서 노드를 만들어나가면 최적 BST를 얻을 수 있다.
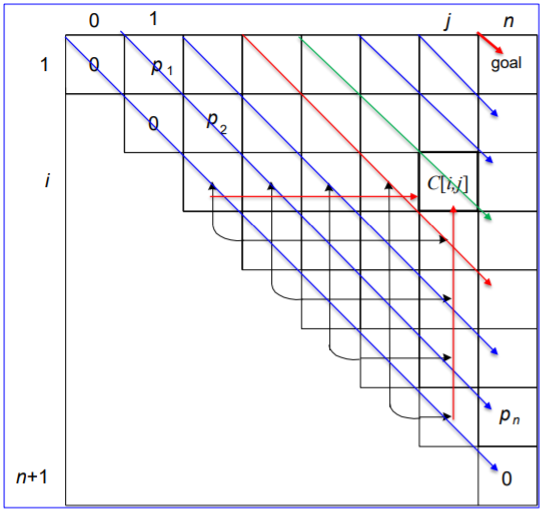
Pseudo Code

최적 BST 파트는 식도 많고 표현하기에 어려움이 많아서 이 글만으로는 이해가 힘들 것 같다. 글을 작성하면서 이러한 게시글을 발견했는데 https://gsmesie692.tistory.com/116 최적 BST에 대한 이해를 하는데 도움이 될 것 같다.
자료 출처
- Introduction to The Design and Analysis of Algorithms / Ananu Levitin
- FOUNDATIONS OF ALGORITHMS / RICHARD E. NEAPORITAN
'알고리즘 > 수업 복습' 카테고리의 다른 글
| Greedy Algorithm Design Pattern 2(탐욕 알고리즘) (0) | 2021.11.08 |
|---|---|
| Greedy Algorithm Design Pattern 1(탐욕 알고리즘) (0) | 2021.10.19 |
| Divide and Conquer design pattern(분할정복) (0) | 2021.10.04 |
| Algorithm Efficiency(알고리즘 효율성) (0) | 2021.09.18 |
| Introduction: 알고리즘에 대해 (0) | 2021.09.06 |




댓글