이 수업의 마지막 챕터인 IPC에 대해 알아보자. 알아볼 내용은 다음과 같다.
- IPC
- 메세지 패싱(Message passing)
- 공유 메모리(Shared memory)
- Signals
- Pipes
- 클라이언트-서버 시스템의 통신
- 소켓
- 원격 프로시저 호출(Remote Procedure Calls, RPCs)
IPC
시스템 내의 프로세스는 독립적(independent)이거나 협력적(cooperating)일 수 있다. 독립된 프로세스는 다른 프로세스의 실행에 영향을 미치거나 받을 수 없다. 협력 프로세스는 데이터 공유를 포함하여 다른 프로세스에 영향을 미치거나 영향을 받을 수 있다. 프로세스가 협력하는 이유는 다음과 같다.
- 정보 공유
- 계산 속도 향상
- 모듈성
- 편의성
이같은 목적을 위해 협력 프로세스는 데이터 교환을 허용하는 IPC 메커니즘이 필요한 것이다. 그리고 IPC의 두 가지 기본 모델은 메세지 패싱 및 공유 메모리이다.
Message-passing Model

메세지 패싱 모델은 협력 프로세스 간에 교환되는 메시지를 통해 통신이 발생한다. fig 1.1처럼 메세지 큐를 사용하여 프로세스간 메세지를 주고 받는 것이다. 이러한 방법은 마이크로 커널(참고)같은 분산 환경에 유용하다. 마이크로 커널은 커널의 일부 기능들을 user mode 서비스로 이동시켰다고 했다. 그럼 다른 사용자 애플리케이션이 이 user-level에서 동작하는 서비스를 이용하기 위해 IPC 통신을 이용해야 한다고 했었다. 이때 사용되는 모델이 바로 메세지 패싱모델이다.
이러한 메세지 패싱 모델의 특징은 일반적으로 시스템 콜을 사용하여 구현된다. 즉 주요 작업(send, receive)등을 할 때 커널이 개입되어야 하는데, 이것 때문에 많은 시간이 소요된다는 단점이 있다.

간단하게 메세지 패싱을 표현하면 다음과 같다. Producer 측에서 send한 것을 Consumer 측에서 받아서 사용한다.
그럼 통신과정에 대해 조금 더 들어가보자. 프로세스 P와 Q가 통신하려한다면 그들 사이의 통신 링크를 설정하고 send/receive/ 방식을 통한 메세지 교환이 이뤄져야 한다. 이때 통신 링크를 구현할 때 물리적으로는 공유 메모리, 하드웨어 버스 또는 네트워크를 사용할 수 있고, 논리적으로는 몇가지 방법이 있다.
- 프로세스가 명시적으로 서로 이름을 지정해야 하는 직접 통신(ex. send(P, message) & receive(Q, message)) 방법, 메세지를 사서함을 통해(메세지 큐라고 생각하자)으로 보내고 받는 간접 통신
- 동기(=blocking)또는 비동기(=non-blocking)
- 용량이 0인 버퍼링(최대 큐 길이가 0), 제한된 용량으로 버퍼링(큐 길이가 n으로 유한), 용량 제한이 없는 버퍼링
Shared-memory Model
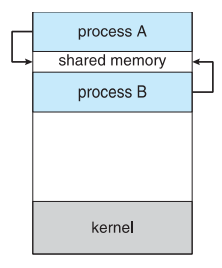
공유 메모리 모델에서는 협력 프로세스가 공유 메모리 영역을 설정한 다음 공유 영역에서 데이터를 읽고 쓰는 방식으로 정보를 교환한다. 일반적으로 공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다. 또한 이 모델에서는 시스템 콜이 공유 메모리 영역을 설정하는 데만 필요하므로 메세지 패싱 모델보다 빠르다. 즉, 일단 설정되면 모든 액세스는 일상적인 메모리 엑세스로 처리되기 때문에 커널의 도움이 필요없는 것이다.
여기서 통신은 OS가 아닌 사용자 프로세스의 제어 하에 있다. 이 모델에 해결해야 할 문제는 사용자 프로세스가 공유 메모리에 액세스할 때 작업을 동기화할 수 있는 메커니즘을 제공하는 방법이다. 두 개의 프로세스가 공유 메모리의 같은 공간에 write를 한다고 할 때 여기에 어떤 값이 쓰일지 확신할 수 없다는 것이다. 이 주제에 대해서는 운영체제 과목에서 다룬다고 한다.
POSIX Shared Memory
POSIX의 공유 메모리를 살펴보자면, 우선 프로세스가 공유 메모리 세그먼트를 생성해야 한다. 바로 공유 메모리가 생성되는 것이 아니라 공유 메모리 세그먼트가 생성되는데, 공유 메모리와 관련된 파일이다. 이는 대부분의 것을 파일 형식으로 관리하려하는 Linux의 의도가 반영된 것이다.
shm_fd = shm_open(name, O_CREAT | O_RDWR, 0666);
ftruncate(shm_fd, 4096);
sprintf(shared memory, "Writing to shared memory");우선 shm_fd()는 'name'에 파일의 이름이 들어가고, 'O_CREAT'라는 것은 현재 프로세스에 공유 메모리를 생성하겠다는 뜻이다. 그리고 'O_RDWR'은 해당 파일을 일기/쓰기 모드로 연다는 것이고 '0666'의 해당 파일의 권한을 설정하는 것이다. shm_fd는 공유를 위해 기존 세그먼트를 여는데 사용되기도 한다. 그리고 ftruncate()를 이용해 공유 메모리에 크기를 설정하면 이제 프로세스는 공유 메모리에 write가 가능해진다.
What about IPC in Linux?
Linux는 프로세스가 서로 통신할 수 있는 풍부한 환경을 제공한다.
- 특정 이벤트 발생에 대해 프로세스에 알리는 메커니즘
- Signal
- 프로세스 간에 데이터를 전달하기 위한 여러 메커니즘
- 공유 메모리
- 메세지 큐(=메세지 패싱)
- Pipes
- 일련의 네트워킹 기능
여기서 두 개는 알아봤고 나머지 3개도 알아보자.
Signals
Signal(시그널이라 하겠음)은 특정 이벤트를 프로세스에 알리는 IPC 메커니즘이다. 이는 사용자 애플리케이션에서 동기적(코드를 진행하면서 발생, ex. 잘못된 메모리 엑세스)으로 발생할 수도 있고 비동기적(외부 이벤트에 의해 발생, ex. 종료)으로 발생할 수도 있다.
그런데 이전에 이것과 SW interrupt라는 개념을 배웠었다. 동기적으로 발생하는 시그널을 SW라고 생각할 수 있는 것이다. 다시 떠올려 보자면 특정 이벤트에 의해 시그널이 생성되고 이 시그널이 프로세스에 전달되고 시그널 핸들러(signal handler)는 해당 시그널을 처리한다. 핸들러에는 커널에 의해 제공되는 default handler와 이를 오버라이딩하여 사용자가 정의하는 signal handler가 있다.

fig 3.1을 보자. signal handler를 정의하기 위해 쓰는 것이 sigaction이라는 구조체와 sigaction()이라는 함수이다. 간략하게만 설명하면 SIGALRM에 대한 핸들러를 sa라는 사용자 정의 핸들러로 변경하겠다는 뜻이다.
그리고 프로세스는 'int kill(pid_t pid, int sig);'라는 함수를 통해 다른 프로세스에게 시그널을 보낼 수 있다(프로세스를 죽일 때만 쓰는게 아님).
Pipes
파이프는 말 그대로 두 프로세스가 통신할 수 있도록 하는 통로 역할을 한다. UNIX는 파이프를 특수한 유형의 파일로 취급하므로 일반적인 read()/write() 시스템 콜을 사용하여 파이프에 액세스할 수 있다. 예를 들어, 파이프를 사용하여 한 프로세스의 출력을 다른 프로세스의 입력으로 보낼 수 있다(I/O에 대한 글에서 언급됐음). UNIX/Linux 및 Windows 시스템에는 일반적인 두 가지 유형의 파이프 ordinary pipe, Named pipe가 있다.
Ordinary pipes

ordinary pipe는 단방향 통신만 허용하고 통신 프로세스 간에 부모-자식 관계가 필요하다. 즉 producer가 한쪽에서 write하고 consumer가 다른 쪽에서 read한다. 따라서 ordinary 파일은 단방향이다.
Named pipes
named pipe는 ordinary pipe보다 강력하다. 통신은 양방향이고, 통신 프로세스간 부모-자식 관계가 필요하지 않다. 그리고 여러 프로세스가 통신을 위해 named pipe를 사용할 수 있고 프로세스가 종료된 후에도 name pipe는 활성화 상태를 유지한다.
Network Structure
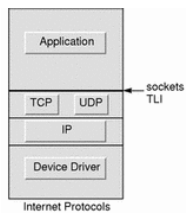
이번에는 네트워크에 대해 알아보자. Linux 커널의 네트워킹은 내부적으로 3개의 계층으로 구현된다.
- 소켓 인터페이스
- 프로토콜 스택(TCP/IP 프로토콜 군)
- IP 프로토콜은 네트워크의 모든 위치에서 서로 다른 호스트 간의 라우팅을 구현
- 그 위에 UDP 또는 TCP 프로토콜이 구축됨
- 네트워크 장치 드라이버: 이더넷 WiFi, 블루투스 등
UDP vs. TCP
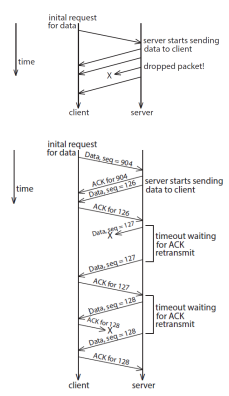
네트워크에서 주고받는 데이터의 단위는 패킷임을 기억하고 좌측 그림을 살펴보자. 첫번째 그림은 UDP(User Datagram Protocol)를 이용한 통신과정인데 별다른 동작없이 단순히 패킷을 보내고 받는 단순한 구조이다. 때문에 전송 도중 패킷이 손실되어도 이를 고려하지 않기에 보낸 패킷을 올바르게 수신할거라고 신뢰할 수 없다. 또한 순서가 바뀌어도 이를 고려하지 않는다. 이처럼 신뢰성은 없지만 전송과정이 단순하여 전송 속도가 빠르다는 장점이 있다.
TCP(Transmission Control Protocol)은 UDP와 다르게 신뢰가능하고 패킷을 순서대로 수신할 수 있다. 좌측 두번째 그림을 보자. 호스트가 패킷을 보낼 때마다 수신측에서는 승인 패킷(ACK)이라는 것을 보내야 한다. 타이머가 만료되기 전에 ACK가 수신되지 않으면 발신자 측은 다시 패킷을 보낸다.
패킷의 시퀀스 번호(seq)를 통해 수신측은 패킷을 순서대로 정렬하고 누락된 패킷을 알 수 있다. UDP와 달리 이러한 과정이 추가되다 보니 상대적으로 느린 전송 속도를 가진다.
Communication in Client-Server Systems
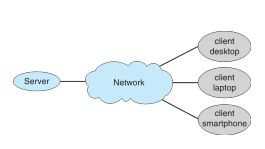
클라이언트-서버 시스템은 어렵게 말하면 서버 시스템이 클라이언트가 생성한 요청을 만족시키는 특수 분산 시스템이다. 대부분의 네트워크 프로세스 통신은 이러한 클라이언트-서버 모델을 따른다. 한 컴퓨터의 프로세스는 서버 역할을 하고 다른 컴퓨터의 프로세스는 클라이언트 역할을 한다. 그리고 클라이언트-서버 시스템에서 통신을 위한 소켓, 원격 프로시저 호출(RPCs)라는 두가지 전략이 있다.
Sockets

소켓은 통신을 위한 endpoint로 정의된다. 네트워크를 통해 통신하는 한 쌍의 프로세스는 한 쌍의 소켓(각 프로세스에 하나씩)을 사용한다. 이때 각 소켓은 고유한 IP 주소 및 포트 조합과 연결된다. fig 6.1에서 각 호스트가 가지는 소켓의 IP 주소와 포트 번호를 확인할 수 있다.
서버는 수신 대기를 위해 지정된 포트를 열고 들어오는 클라이언트의 요청을 기다린다. 요청이 수신되면 서버는 클라이언트 소켓의 연결을 수락하여 연결을 완료한다. 위에서 말했듯이 모든 연결은 고유해야 한다. 즉, 각 연결은 고유한 소켓 쌍으로 구성되야 하는 것이다. 1024번 미만의 포트는 well-known 포트이며 표준 서비스에 사용된다. 예를 들어 특정 서비스를 구현하는 well-known 포트들에는 Web/HTTP 서버(80), FTP 서버(21), SSH 서버(22) 등이 있다.
클라이언트가 연결 요청을 시작하면 해당 OS에서 포트를 할당받는데 이 로컬 포트에는 1024보다 큰 임의의 숫자가 있다.
Socket Programming in C/C++
Unix 계열 OS는 장치, 파일 및 네트워크를 동일한 방식으로 상호 작용하려고 한다. 앞서 말했듯이 여기서 이러한 OS는 모든 파일 시스템의 일부로 취급된다. 소켓 시스템 호출은 네트워크를 통한 프로세스 간 통신에 사용된다. 이 통신 방법은 기본적인 파일 입출력(open, read/write, close)과 유사한 3단계(connect, send/receive data, terminate)를 따른다.
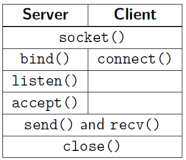
버클리 소켓(Berkeley Sockets)은 네트워크 통신을 위해 이러한 추상화를 구현하는 역할을 한다. 밑의 fig 6.4는 TCP 서버의 버클리 소켓 예시이다.

우선 소켓을 생성한 뒤에 IP 주소와 포트 번호를 부여한다. 그리고 이 정보를 이용해 소켓을 open한 뒤에 클라이언트 요청을 기다린다. 클라이언트의 연결 요청이 들어오면 서버는 연결을 허용한다. 네트워크의 주요 함수(시스템 콜)을 살펴보자. 간략하게만 설명하니 자세한 사항은 따로 찾아보자.
Socket()
socket() 시스템 콜에는 도메인, 통신 유형, 프로토콜의 3가지 인수가 있다.
- 도메인
- 인터넷 도메인: AF_INET or PF_INET for IPv4, AF_INET6 or PF_INET6 for IPv6. 'AF_~, PF_~'는 주소체계, 프로토콜이라는 의미가 서로 다르지만 같은 값을 가진다.
- Unix 도메인: AF_UNIX or PF_UNIX or AF_LOCAL or PF_LOCAL. 문자의 의미는 다르지만 모두 같은 값
- 동신 유형
- SOCK_STREAM: TCP/IP
- SOCK_DGRAM: UDP/IP
소켓은 네트워크 통신이 발생하는 정수 식별자를 제공한다. 새로 생성된 소켓은 아직 전화를 거는데 사용되지 않은 전화와 비슷하다. 소켓 식별자는 아직 연결하는데 사용되지 않았다.
bind()
서버는 일반적으로 소켓을 바인딩하여 연결을 수신할 IP와 포트를 정의한다. 구조체 'sockaddr_in'은 소켓이 사용되는 방법에 대한 정보를 담는다.
listen()
int listen(int sockfd, int backlog)바인딩 후 서버는 통신을 기다리기 위해 listen()을 호출할 수 있다. 여기서 두번째 인수인 'backlog'는 서버가 다른 통신을 처리하는 동안 대기할 수 있는 연결의 수를 의미한다. 이를 초과는 연결을 시도하는 클라이언트에는 오류 값(-1)이 반환된다.
accept()
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen)서버는 클라이언트가 보낸 연결 시도를 수신하면 연결을 수락할 수 있다. accpet()는 데이터가 전송될 두 번째 소켓을 반환한다. 이렇게 하면 원래의 소켓은 추가 연결을 계속 수신할 수 있다.
connect()
int connect(int sock, struct sockaddr *serv_addr, int addrlen)클라이언트는 바인딩과 유사한 단계를 수행하지만 수신을 대기하는 대신 적극적으로 호출하여 연결을 설정한다. 즉 connect()는 연결을 설정하기 위해 서버를 호출하는데 사용된다.
send() & receive()
ssize_t send(int sockfd, const void *buf, size_t len, int flags)
ssize_t recv(int sockfd, void *buf, size_t len, int flags)클라이언트와 서버 간에 연결이 설정되면 데이터를 송수신할 수 있다. send() 시스템 콜은 소켓 식별자, 데이터를 가리키는 주소, 보낼 바이트 수, 플래그 설정의 4가지 인수를 사용하고. recv() 시스템 콜 역시 소켓 식별자, 데이터를 가리키는 주소, 수신할 최대 바이트 수, 플래그 설정의 4가지 인수를 사용한다.
서버와 클라이언트 모두 send(), recv()를 실행할 수 있다. send(), recv() 함수는 인수가 주어진 주소의 데이터 유형보다는 주소와 바이트 수를 정의한다는 점에서 fread() 및 fwrite() 함수와 유사하다.
close()
통신이 완료되면 서버와 클라이언트 모두 해당 소켓을 닫아야 한다. close() 시스템 콜은 연결을 종료하기 위해 OS에서 일련의 작업을 초기화하고 통신에 사용된 자원을 회수하게 한다. 따라서 소켓은 OS가 닫기를 완료할 때까지 몇 초의 시간이 소요되기에 netstat 프로그램(명령어) 목록에 계속 나타날 수 있다.
RPCs
소켓을 사용한 통신은 분산 프로세스 간의 저레벨(low-level) 통신 형식으로 간주된다. 왜냐하면 소켓은 통신하는 프로세스 사이에서 구조화되지 않은 바이트 스트림만 교환할 수 있기 때문이다(일반적&효율적). 이러한 데이터를 구조화 하는 것은 클라이언트나 서버 애플리케이션의 몫이다.
RPCs는 조금 더 높은 레벨(high-level)의 통신 방식이다. 이는 가장 일반적인 형태의 원격 서비스 중 하나로, 네트워크로 연결된 시스템에서 프로세스 간의 프로시저 호출을 추상화하는 방법이다. 이 방법은 클라이언트-서버 컴퓨팅에서도 유용하고 Android에서 동일한 시스템에서 실행 중인 프로세스 간 IPC 형태로 RPCs를 사용한다.
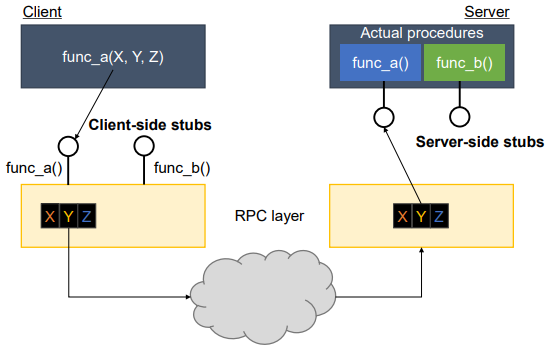
fig 6.5를 통해 구체적으로 살펴보자. 원래 함수는 같은 프로세스 안에서 정의된 것을 사용하는게 일반적이다. 그런데 여기서는 서버에 정의된 함수 func_a()와 func_b()를 클라이언트에서 마치 로컬 함수인 것처럼 사용하려고 한다.
클라이언트에서는 X, Y, Z라는 파라미터를 넣어 func_a를 호출하는데 이때 버퍼에 해당 파라미터를 일렬로 담아(직렬화) 서버 쪽에 패킷으로 전송하는 것이다. 서버 측에서는 수신한 것들을 파싱하여 파라미터로 복원해준 뒤 이를 이용하여 func_a() 서버측에서 실행한다.
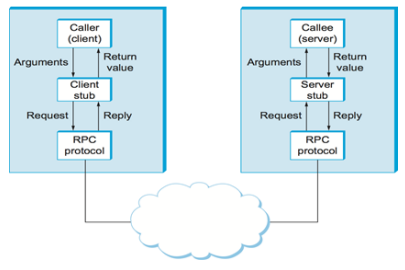
RPC의 의미는 클라이언트(=발신자)가 로컬에서 프로시저를 호출하는 것처럼 원격 호스트(= 수신자)에서 프로시저를 호출할 수 있도록 한다는 것이다. RPC 시스템은 서버/클라이언트 측에 stubs을 제공하여 통신이 발생하도록 허용하는 세부 정보를 숨긴다.
여기서 stubs은 서버 측에서 실제 절차를 추상화하는 프록시 객체이다. 클라이언트 측 stubs은 서버를 찾고 파라미터를 직렬화한다. 즉 네트워크에서 전송하기 위한 형태로 파라미터를 패키징하는 것이다. 서버 측 stubs은 이 메시지를 수신하고 직렬화된 파라미터의 압축을 풀고 서버에서 프로시저를 수행한다.
자료 출처
- Adam Hoover, “System Programming with C and Unix, Addison Wesley 2010.
- Abraham Silberschatz, Peter Baer Galvin, and Greg Gagne, “Operating System Concepts (10th Edition), Wiley 201
'시스템 프로그래밍' 카테고리의 다른 글
| Process and Thread Management (0) | 2021.12.25 |
|---|---|
| I/O Systems and Operations (0) | 2021.11.29 |
| OS Structures & Linux Overview (0) | 2021.11.12 |
| Operating Systems(OS) Overview (0) | 2021.11.05 |
| Linkers and Loaders (0) | 2021.11.01 |




댓글