이전까지는 어셈블러에 대해 알아보았다. 어셈블러는 어셈블리어를 기계가 이해할 수 있는 기계어(object code)로 변환시키는 역할을 한다고 했다. 이제 그 다음 과정을 위해 사용되는 링커(Linker)와 로더(Loader)에 대해 알아보자.
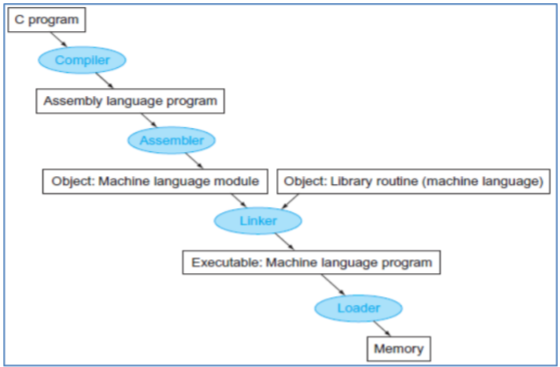
fig 1을 통해 C와 같은 고급 언어 프로그램의 번역 계층을 다시 살펴보자. 번역 과정의 속도를 높이기 위해 일부 단계를 건너뛰거나 결합하기도 하지만 기본적으로 4단계를 따른다.
- 먼저 어셈블리 언어 프로그램으로 컴파일
- 어셈블러를 통해 기계어로 된 객체 모듈로 조립된다.
- 링커는 여러 모듈을 라이브러리 루틴과 결합하여 모든 참조를 확인한다.
- 로더는 기계어 코드를 프로세서가 실행할 적절한 메모리 위치에 배치한다.
여기서 링커와 로더에 대한 내용은 당연히 생소할 것이다. 그리고 이제 알아볼 것이기도 하다.
Linkers
Linker가 있는 이유는 별도의 컴파일(Separate compilation)을 위해서이다. 프로그램은 논리적으로 관련된 서브루틴 및 자료구조 모음 등이 담긴 여러가지의 소스파일로 이루어져 있고 이 각각의 소스파일을 어셈블러가 읽어서 각각의 object file을 만드는 것이다. 때문에 하나의 소스파일을 수정해도 다른 모든 소스파일을 다시 assemble할 필요는 없다. 아무튼 이렇게 만들어진 각각의 object file들을 엮어서 하나의 프로그램으로 만들어야 하는데 이때 사용되는게 바로 링커인 것이다.

즉 fig 2와 같이 프로그램은 여러개의 파일로 나눠질 수 있고, 각각의 파일은 따로 컴파일 된다. 하지만 우리는 한 파일에서 다른 파일의 내용을 참조해야 한다. 이러한 참조 관계를 컴퓨터가 인식하기 위해서 링커가 object 파일들을 엮어서 하나의 실행가능한 파일을 만든다. 더 자세히 알아보자.
Linker
링커는 각 객체 모듈의 재배치 정보 및 기호 테이블(SYMTAB)를 사용하여, 독립적으로 조립된(assembled) 기계어 프로그램을 결합하고 정의되지 않은 모든 레이블을 실행 파일로 해결하는 시스템 프로그램이다. 링커는 컴퓨터에서 실행가능한 실행 파일을 생성한다. 일반적으로 이 파일은 object file과 같은 형식을 가지고 있으나 모든 해결되지 않았던 참조가 해결되었다는 차이점이 있다.
요약하면 링커가 수행하는 작업은 3가지이다.
- 프로그램에서 사용하는 라이브러리 루틴을 찾기 위해 프로그램 라이브러리(=미리 작성된 루틴)를 검색
- 각 객체 모듈이 점유할 메모리 위치를 결정하고 절대 참조를 조정하여 명령을 재배치
- 개체 파일 간의 외부 참조 해결
Loader
이번에는 로더에 대해서도 알아보자. 링커에 의해 생성된 프로그램이 실행되기 전에 프로그램은 디스크와 같은 보조 저장 장치에 위치해 있다. OS의 로더는 프로그램을 메모리로 가져와 실행을 시작한다. 따라서 프로그램을 시작하기 위해 로더는 다음 단계를 따른다. 그 전에 프로그램이 메모리에 할당되면 기본적으로 fig 3와 같은 모양으로 할당된다.
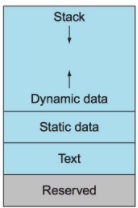
- 실행 파일의 헤더를 읽고 텍스트 및 데이터 세그먼트의 크기를 결정한다.
- 스택 세그먼트와 함께 텍스트 및 데이터 세그먼트에 대해 충분히 큰 새 주소 공간(프로그램용)을 생성한다.
- 실행 파일의 명령(text segment)과 데이터(data segment)를 새 주소 공간(메모리)으로 복사한다.
- 매개변수(있는 경우에)를 기본 프로그램의 스택에 복사한다.
- machine register를 초기화하고 스택 포인터를 첫번째 여유 위치로 설정한다.
- 스택에서 레지스터로 매개변수를 복사하고 프로그램의 메인 루틴을 호출하는 시작 루틴으로 점프한다. 메인 루틴에서 돌아올 때(returning) 시작 루틴은 종료 시스템 호출(exit system call)로 프로그램을 종료한다.
Loader
로더는 object program을 메인 메모리에 저장하여 실행하는 로딩 기능을 수행하는 시스템 프로그램이다. 많은 로더는 재배치(relocation)이나 연결(linking)도 지원한다. 재배치는 object program에서 절대 주소를 수정한다. 연결은 둘이상의 분리된 object program을 결합한다.
때문에 로더가 오직 loading만을 수행한다면 absolute loader, 재배치나 연결 기능도 수행한다면 linking loader로 분류할 수 있다.
Absolute Loader
우선 간단한 구조를 가지는 absolute loader에 대해 먼저 알아보자. object code의 레코드에 대해 이해하고 있어야한다. 모든 기능은 단일 pass에서 수행된다. 우선 헤더 레코드를 확인하여 로드를 위해 올바른 프로그램이 제공되었고 사용 가능한 메모리 공간에 할당할 수 있는지 확인한다. 그리고 텍스트 레코드를 읽을 때 포함된 object code가 메모리의 표시된 주소로 이동된다. END 레코드에 다다르면 로더가 지정된 주소(프로그램의 시작 주소)로 점프하여 로드된 프로그램의 실행을 시작한다.

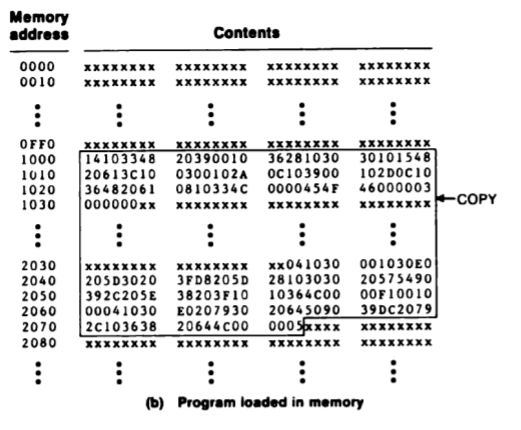
fig 4와 같은 object code가 있다고 하면, 우선 H record를 확인하여 주소 1000부터 시작함을 확인하고 107A만큼의 공간이 있는가 판단한다. T record를 거치면서 해당 object code가 메모리로 이동하고 E record를 만나게 되면 시작 주소 1000으로 점프하여 프로그램의 실행을 시작하는 것이다. 해당 과정을 거쳐 메모리에 프로그램이 로드되면 메모리의 모습은 fig 5와 같을 것이다.
※ Boot Loader
해당 로더는 컴퓨터를 처음 켜질 때 실행되는 특수한 유형의 로더이다. 우선 실행할 첫 번째 프로그램(보통 OS)을 로드한다. 그리고 HW 로직이 ROM의 주소 0의 프로그램을 읽는다. ROM은 제조업체에서 설치하는데 ROM에는 부트스트랩 프로그램(부트 로더)과 하드웨어를 제어하는 기타 루틴(ex. BIOS)이 포함되어 있다. absolute loader와 유사하게 재배치&연결을 수행하지 않는다.
Pros & Cons
absolute loader의 장단점을 알아보자. 우선 장점은 1 pass로 수행되기에 단순성과 효율성을 가진다. 하지만 프로그래머는 프로그램이 assemble 될 때 프로그램이 메모리에 로드될 실제 주소를 지정해야 한다. 이는 더 크거나 고급 기계에서는 불가능하다. 그리고 모든 서브루틴에는 사전에 할당된 절대 주소가 있어야 한다. 이는 서브루틴 라이브러리를 효율적으로 사용하기 어렵게 만든다. 그리고 여러 프로그램을 함께 실행할 수 없다.
Linking Loader
우리는 SIC/XE라는 기계를 바탕으로한 프로그램을 예시로 계속 들었다. linking loader는 이러한 SIC/XE 시스템 및 대부분의 최신 컴퓨터에서 사용하기 적합한 더 복잡한 로더이다. 해당 로더는 프로그램 재배치(relocation), 연결(linking), 단순 로딩 기능을 수행한다.
로더에서 재배치가 구현되는 방식은 기계의 특성에 따라 다르다. 보통 object program의 일부로 재배치를 지정하는 두가지 방법이 존재한다. 하나는 Modification record이고 다른 하나는 Relocation bit이다.
Relocation with M record
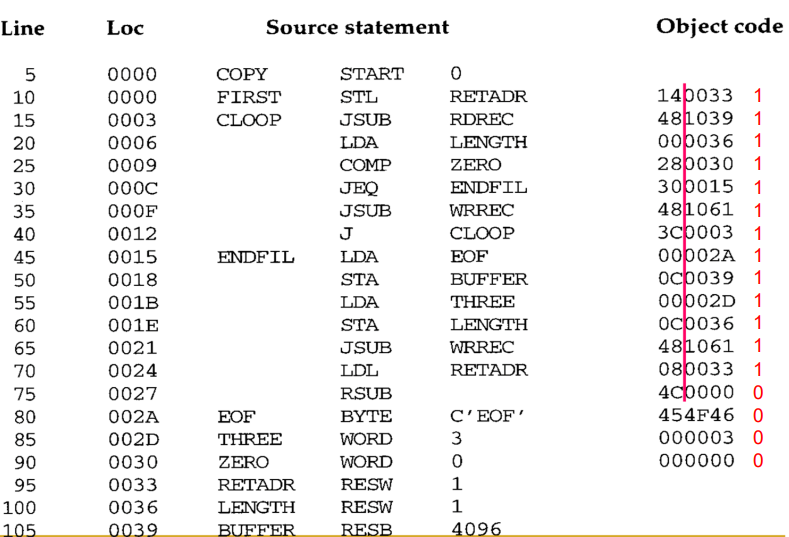
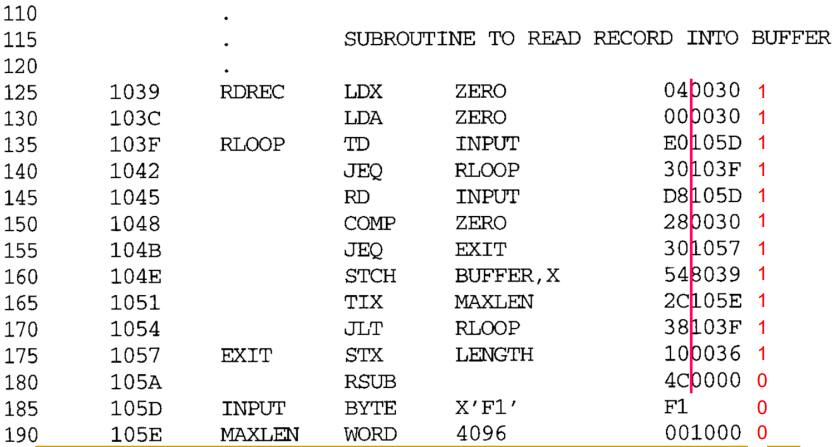
M record는 object program의 일부에서 재배치를 지정하는 일반적인 방법이다. 이에 대해서는 어셈블러를 할 때 확인해봤었다. 어셈블러가 M record를 object program에 넣어주면 이제 로더가 이를 해석하여 적절하게 재배치를 하면 되는 것이다. fig 7은 fig 6(Assembler(2)에서 다룸)에 대한 object code이다.


현재 변경해야 하는 명령어들은 모두 immediate addressing을 사용하고 있다. 현재 addr field의 값은 RDREC, WRREC이 프로그램 시작주소에서 얼마나 떨어져 있는가를 나타낸다. 하지만 해당 레이블의 절대적인 주소는 현재 addr field값에 프로그램 시작주소인 COPY를 더한 값이다. 때문에 M record에서는 해당 addr field에 프로그램 시작 주소를 가리키는 symbol인 COPY를 더하라고 되어 있는 것이다.
하지만 M record를 이용한 재배치는 SIC 기본 버전 같은 모든 기계 아키텍처에 적합하지는 않다. 밑의 fig 8은 표준 SIC용으로 작성된 재배치 가능 프로그램이다. 여기서는 대부분의 명령어가 direct addressing을 사용하기 때문에 M record가 너무나 많이 추가될 것이다. 때문에 program size 측면에서 너무나 비효율적이다.

Relocation with Bit Mask
이러한 경우네는 object program의 일부로 재배치를 지정하는 다른 방법인 Relocation bit mask를 사용한다. 주로 direct addressing을 사용하고 고정된 명령어 형식을 갖는 기계에 유용하다(SIC!!).
계속 봐왔던 M record를 한번 살펴보자. [수정할 주소, 길이]라는 형식을 가지고 있었는데 여기서는 고정된 명령어 형식을 갖기에 '길이'는 제거할 수 있다. 그리고 '수정할 주소' 대신에 bit-vector(=relocation bit)를 사용할 수 있다. 이는 1 or 0으로 설정할 수 있다. '1'인 경우에는 재배치 시 프로그램의 시작 주소가 해당 word에 추가되고 '0'인 경우에는 수정이 불필요하다. 이런 방식을 적용한 object code가 바로 fig 9이다.

첫번째 T record를 예로 들어보자. 해당 레코드의 object code의 길이를 표현하는 열 이후에 'EFC'를 확인할 수 있다. 이진수로 풀어보면 '1111 1111 1100'이다. 가장 왼쪽비트부터 첫번째 instruction의 relocation bit가 된다. 이런식으로 확인해보면 해당 레코드는 모두 addr field가 수정되어야 함을 알 수 있다.
Program Linking
다시 과정을 거슬러 올라가서 Linking에 대해서 알아보자. 간략하게 요약하자면 하나의 프로그램은 관련된 모든 Control Section(CS, 이전 게시글에 대한 이해가 필요)들이 결합된 logical entity이다. 그런데 로더의 관점에서는 프로그램이라는 개념이 없고 CS들은 각각 링크하고 재배치하고 로드할 독립된 개체들인 것이다.
EXTDEF & EXTREF
EXTDEF, EXTREF라는 directives에 대해서는 전 게시글에서 살펴보았다. 다시 정리하자면 (현재)CS에서 정의된 EXTDEF(외부 정의)는 다른 섹션에서 사용할 수 있는 '외부 기호(external symbol)'라고 하는 기호의 이름을 지정한다. 'EXTDER BUFFER'라고 하면 현재 CS에 있는 BUFFER가 다른 CS에서도 사용할 수 있는 '외부 기호'가 되는 것이다.
EXTREF(외부 참조)는 (현재) CS에서 어떤 '외부 기호'들을 사용할 지 정의한다. 'EXTREF RDREC'라고 하면 다른 CS에서 EXTDEF로 정의된 RDREC이라는 외부 기호를 현재 CS에서 사용할 수 있게 되는 것이다. 이제 예시로 확실히 이해해보자.
Example of Linking

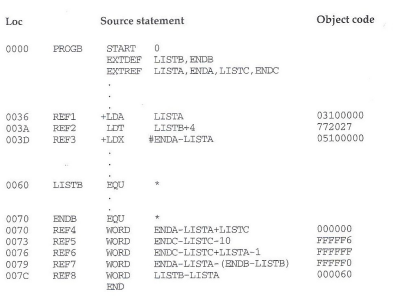

fig 10의 각각의 코드들은 다른 CS(PROGA, PROGB, PROGC)에 속해있다. 각 섹션별로 LISTA/B/C, ENDA/B/C가 정의되어 있고 REF1~REF8까지 모두 동일한 reference를 사용하는 statement를 각 CS들이 가지고 있다. REF1~REF3까지는 instruction의 operand, REF4~REF8까지는 data word의 값을 나타내고 있다. 주목해야 할 것은 이렇게 3개의 CS에서 동일한 reference가 적혀있지만 이들을 다루는 방법에는 차이가 있다는 것이다. 그 중에서 몇가지를 자세히 살펴보자.
fig 10.1에서 LISTA는 local reference이다. 때문에 REF1에서 'TA-(PC)=40-23=1D'처럼 disp를 계산한다. 하지만 나머지 CS에서 REF1을 참조하려면 일단은 format4 instruction을 써야하고 아직 프로그램 로드전이니 addr을 0으로 채운다. 그리고 해당 addr을 나중에 수정하기 위해 M record를 추가할 것이다.
이번에는 각 CS의 REF4가 어떻게 처리되는지 살펴보자. 우선 fig 10.1에서는 ENDA, LISTA모두 local reference이다. 두 symbol이 로드시 메모리에 위치할 때의 주소는 '(프로그램 시작 주소)+(현재 CS에서의 상대주소)' 형태이나 이들을 빼주면 (프로그램 시작 주소)는 사라진다. 결국에는 '54-40=14'라는 절대적인 값을 얻을 수 있다. 그리고 LISTC의 값을 빼주어야 하는데, 이는 external symbol이므로 나중에 M record로 처리를 해야한다. fig 10.2에서 REF4의 ENDA, LISTA, LISTC는 모두 external symbol이고, fig 10.3에서는 LISTC만 상대 주소(0030)을 가지니 일단은 이것만 object code에 기록된다.
그럼 이제 fig 10의 어셈블리 코드가 object code로 변환된 fig 11을 살펴보면서 위에서 말했던게 모두 적용이 되었는지 살펴보자.



우선 fig 11.2, 11.3의 첫번째 M record를 보자. 해당 레코드들 모두 external symbol인 LISTA의 주소를 0으로 채웠던 addr field에 더해라는 내용을 확인할 수 있다. 그리고 fig 11.1의 두번째 M record에서는 external symbol인 LISTC의 주소를 '000014'에 더하라는 내용을 확인할 수 있다. fig 11.2의 4~6번째 M record에서는 ENDA, LISTA, LISTC의 주소를 모두 더하거나 빼라는 내용을 확인할 수 있다.
fig 11.3의 5~7번째 M record는 조금 다른 경우인데 분명 fig 11.3의 REF4에서 external symbol은 ENDA, LISTA 두 개 뿐인데 세번째 CS의 시작 주소를 가리키는 symbol인 PROGC의 값을 더하고 있다. 그 이유는 LISTC만 상대적인 reference이기 때문에 이를 메모리 상의 절대적인 주소로 변환해주기 위해 해당 CS의 시작 주소를 더해준 것이다. 그럼 이러한 M record가 적용된 후 이것들이 메모리에 올라왔을 때의 모습도 확인해보자.

즉 재배치 및 linking이 수행된 후 메모리에 로드되었을 때, REF4~8은 3개의 CS에서 동일한 값을 생성했다. 이는 위에서도 확인해 봤듯이 동일한 expression으로 계산되기 때문이다. 하지만 REF1~3처럼 instruction의 operand인 경우에는 CS들이 어디에 로드되는지에 따라 다른 값이 나타난다.

fig 13은 PROGA의 REF4의 linking 과정이다. M record의 +LISTC를 읽는다. 이는 LISTC의 메모리상 절대주소를 더해야 하는 것이다. 때문에 PROGC의 시작주소와 해당 CS에서의 LISTC 상대주소를 더한뒤에 이 값을 '000014'에 더해주고 이 값이 메모리에 로드되는 것이다.
Algorithm & Data Structures for a Linking Loader
Linking loader는 Modification Record를 사용하여 linking과 재배치(relocation)를 동시에 해결하려고 한다. 때문에 더 복잡한 알고리즘을 가진다. linking까지 해줘야 하기 떄문에 당연히 absolute loader보다 복잡한 알고리즘을 가진다. 큰 차이점은 input(여러 CS의 집합)에 대해 2-pass를 이용한다는 것이다.
우선 Pass 1에서는 모든 external symbol에 주소를 할당한다. 우선 PROGADDR과 CSADDR이라는 변수를 사용하여 각 모듈(=CS)의 위치를 결정한다. PROGADDR은 링크된 프로그램이 메모리에 로드될 때의 시작주소를 나타내는데 기본적으로 OS한테 넘겨받는다. 즉 OS가 메모리에서 어디가 비어있는지 확인하고 로드될 위치를 정해주는 것이다. CSADDR은 현재 로더에 의해 스캔된 각 CS에 할당된 시작 주소이다.
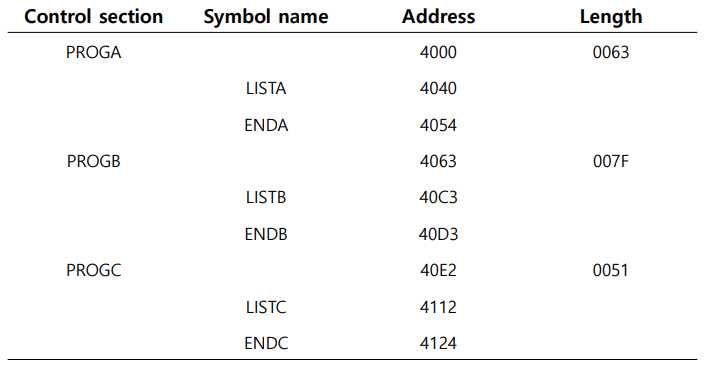
그리고 external symbol table(ESTAB)을 준비한다. 이 자료구조는 각 external symbol의 정보를 저장하는데 사용되는데 [CS, symbol이름, symbol 주소]가 저장된다. fig 14 같은 형식을 가진다. 이러한 ESTAB를 이용하여 pass-2에서 실제 linking과 relocation에 사용이 된다.
ESTAB를 생성하는 pass-1의 알고리즘은 다음과 같이 표현될 수 있다.

Pass 2에서는 실제 로딩, 재배치, linking이 수행된다. M record의 경우에는 ESTAB을 이용하여 주소를 찾는다. 그리하여 코드 자체의 M record에 정의된 대로 절대 주소를 수정한다. 그리고 로드된 프로그램에 control을 넘긴다. 해당 알고리즘은 다음과 같이 표현될 수 있다.

Dynamic Linking
방금전까지 다뤘던 linking은 일반적으로 static linking이라고 한다. 이는 프로그램 실행전에 모든 필요한 object code들이 메모리에 load&linking이 된다는 의미이다. 지금 알아볼 dynamic linking은 프로그램 실행 도중 어떤 object code가 필요할 때 그때 해당 코드를 메모리에 로드하고 linking을 수행하는 것이다.
우리가 C program을 작성할 때 외부에서 작성한 라이브러리를 사용한다고 하자. 만약 프로그램 실행전에 필요한 라이브러리들이 메모리에 로드&linking이 된다면 static linking이라고 하고, 만약 c 프로그램이 동작 중에 외부 C 라이브러리의 메소드 호출이 필요할 때 해당 c 라이브러리가 load&linking이 된다면 이는 dynamic linking인 것이다.
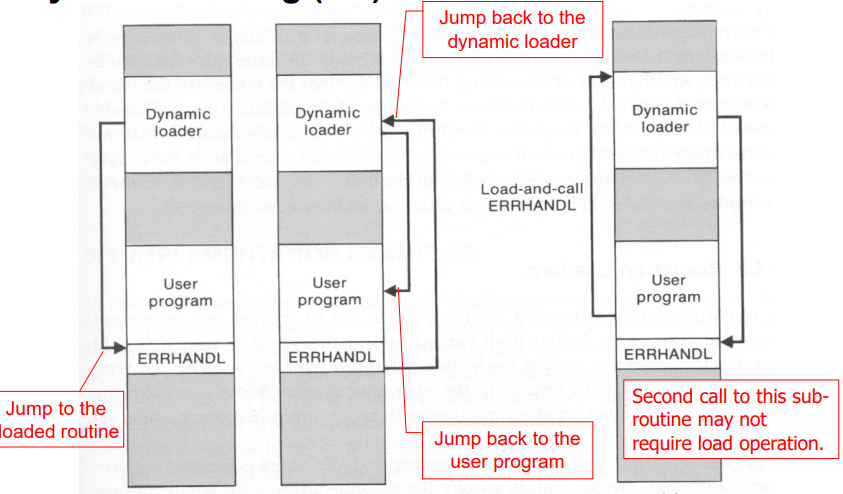
그럼 dynamic linking이 어떤 점에서 이점을 갖고 있을까? 바로 상당한 시간 및 메모리 공간 절약이 가능하다는 것이다. 어떤 라이브러리 전체를 로드하고 linking 하는 것이 아니고 프로그램에서 필요한 일부만을 로드하고 linking하기 때문이다. 또 하나의 장점은 여러 프로그램이 하나의 서브루틴 or 라이브러리 사본을 공유할 수 있다는 것이다. fig 17에서 dynamic linking의 과정을 확인할 수 있다.

자료 출처
- “Computer Organization and Design (5th Edition)” by Patterson & Hennessy]
'시스템 프로그래밍' 카테고리의 다른 글
| OS Structures & Linux Overview (0) | 2021.11.12 |
|---|---|
| Operating Systems(OS) Overview (0) | 2021.11.05 |
| Assemblers (4) (0) | 2021.10.15 |
| Assemblers (3) (0) | 2021.10.15 |
| Assemblers (2) (0) | 2021.10.14 |




댓글