이전에 어셈블러는 기계에 따라 내부의 구현이 달라질 수 있다고 했다. 그럼에도 어셈블러는 기계 아키텍처와 관련되지 않은 독립적인 몇 가지 특징들을 가진다. 이러한 기능의 유무는 기계 아키텍처보다 프로그래머의 편의성 및 SW 환경과 같은 문제와 더 밀접하게 관련되어 있다.
여기서는 이에 대한 5가지 특징들에 대해 살펴보고자 한다.
- Literal
- Symbol definitions
- Expressions
- Program Blocks
- Control sections
위와 같은 특징이 적용된 코드를 살펴보자. 프로그램의 내용은 이전과 동일하다.
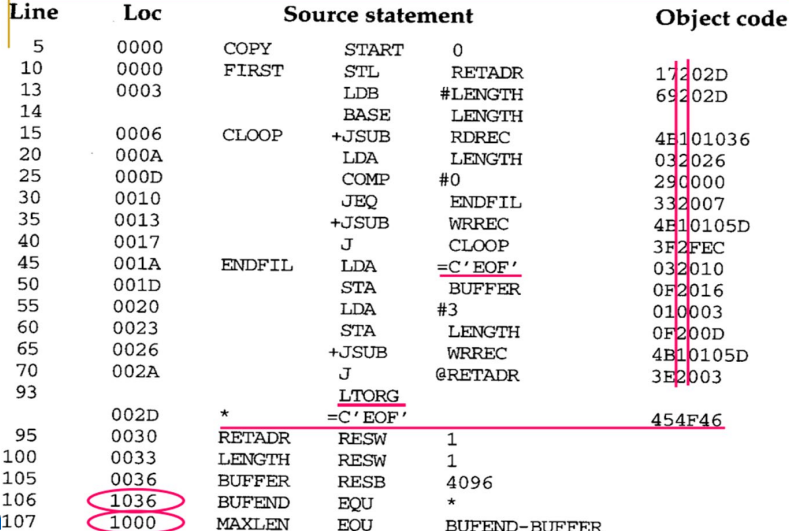


이제 위에서 언급한 특징들에 대해 자세히 살펴보면서 위의 변화된 점들을 이해해보자.
Literals
프로그래머가 상수 operand(피연산자)의 값을 instruction의 일부로 작성할 수 있다면 편리할 것이다. 이렇게 한다면 프로그램 내의 다른 곳에서 상수를 정의하기 위해 상수에 대한 레이블을 구성할 필요가 없다. 이러한 피연산자는 명령에서 문자 그대로 명시되어 있기 때문에 "리터럴(Literal)"이라고 불린다.
리터럴은 접두사 '='로 식별되며, 그 뒤에 BYTE 문에서와 동일한 표기법을 사용하여 리터럴 값을 지정한다.

fig 2를 확인해보자. 하고자 하는 것은 register A에 'EOF'라는 문자열을 넣는 것이다. 이전에는 EOF라는 이름을 가지는 레이블에 공간을 할당하여 'EOF'라는 문자열을 담았다. 그리고 LDA라는 명령어를 통해 EOF레이블 내의 값을 참조하여 register A에 'EOF'를 가져왔다. 하지만 이제는 단순히 '=C'EOF''를 통해 register A에 'EOF'를 넣게 할 수 있다.
Literals vs. Immediate Operand
"엥 이거 저번 게시글에 있었던 immdiate addressing/operand 아닌가?"라고 생각했었다. 때문에 이 둘의 차이를 이해하는 것은 중요하다.
immediate addressing에서 피연산자 값은 machine instruction의 일부로 조립된다. 즉 immediate value는 그 스스로 machine instruction의 내부에 존재한다. 예를 들어 Line 55(LDA #3 010003)를 살펴보자. 3이라는 상수가 address field에 그대로 들어간다.
리터럴에서, 어셈블러는 다른 메모리 위치에서 지정된 값을 상수로 생성한다. 이렇게 생성된 상수의 주소는 machine instruction의 대상 주소로 사용된다. 즉 리터럴 값은 메모리에서 가져온다. 즉 fig 2에서 우리는 EOF와 관련된 레이블을 만들어 공간을 할당하지 않았지만 어셈블러가 해당하는 공간을 만들고 참조하여 거기서 'EOF'를 가져오는 것이다. 어떻게 이것이 가능한건지 계속해서 알아보자.
Literal Pool
어셈블러는 프로그램에 사용되는 모든 리터럴 피연산자를 하나 이상의 리터럴 풀(Literal Pool)로 수집한다. 기본 위치는 프로그램 끝에 위치한다. fig 1의 맨 마지막 줄을 확인해보자. 이 경우 풀은 단일 리터럴 '=X'05''로 구성된다. 그러나 어떤 경우에는 프로그래머가 풀의 위치를 object program의 다른 위치에 선언할 수 있다.
바로 어셈블러 directive인 LTORG(fig 1의 93번 line)를 사용하는 것이다. 어셈블러가 LTORG 문을 만나면 이전 LTORG(또는 프로그램 시작) 이후 사용된 모든 리터럴 피연산자를 포함하는 리터럴 풀이 생성된다. 왜 이렇게 리터럴 풀을 나누게끔 하는걸까? 만약 모든 리터럴 피연산자가 END이후에 위치하는데프로그램 초반에 리터럴을 사용하게 되면 disp를 12-bit로 채우지 못 할 수 있기 때문이다. 그래서 리터럴 피연산자를 이를 사용하는 명령어와 가까이 위치시켜야 한다.
Duplicate Literals
대부분의 어셈블러는 중복된 리터럴(= 프로그램에서 둘 이상의 위치에 사용된 것과 동일한 리터럴)을 인식하고 지정된 데이터값의 복사본 하나만 저장한다. 즉 Line 215, 230에 동일한 리터럴 피연산자 '=X'05''가 사용되는데 이 값을 가지는 데이터 영역은 하나만 생성되어 두 명령어는 리터럴 풀의 동일한 피연산자 주소를 참조한다.
How does the Assembler handle Literal Operand?
그럼 어셈블러가 리터럴 피연산자를 어떻게 다루는지 알아보자.
우선 LITAB(Literal Table)라는 자료구조를 사용한다. 사용된 각 리터럴에 대해 테이블에는 [리터럴 이름, 피연산자 값 및 길이, 리터럴 풀에 놓였을 때 피연산자에 할단된 리터럴 주소]가 포함된다.
Pass 1에서는 각 리터럴 피연산자들이 인식된다. 어셈블러는 지정된 리터럴 이름을 LITAB에서 검색한다. 발견이 됐다면 따로 조치를 하지 않지만 그렇지 않다면 LITTAB에 리터럴이 추가된다. 이때 주소를 지정하지 않고, 코드가 LTORG나 END일 경우에 LITAB에서 리터럴 주소를 할당한다.
Pass 2에서는 각 리터럴 피연산자는 해당 주소로 변환된다. object code 생성에 사용할 피연산자 주소는 발견된 각 리터럴 피연산자에 대해 LITTAB를 검색하여 얻는다. 그리고 리터럴의 데이터 값이 object program에 삽입된다.
Symbol Definitions
이제 또다른 특징인 Symbol Definitions에 대해 알아보자. 대부분의 어셈블러는 프로그래머가 기호(symbols)를 정의하고 값을 지정할 수 있는 어셈블러 directive를 제공한다. EQU(equate)는 주요 기능이 symbol 정의인 어셈블러 directives이다. EQU의 일반적인 사용 형태는 'symbol EQU value'이다. 숫자 값 대신 가독성을 향상시키는데 사용할 수 있는 기호 이름을 설정한다. 변수라고 생각하면 이해가 쉽겠다.

4096이란 값을 EQU를 이용하여 MAXLEN이라는 의미하는 값이 되게 했다. 그래서 operand에 #MAXLEN을 넣어줘도 object code는 동일하다. MAXLEN이라는 의미 있는 이름을 설정해서 가독성을 높였다.
Symbol Definitions with EQU
어셈블러가 EQU문을 만나면 MAXLEN을 SYMTAB(값은 4096)에 입력한다. 이후 LDT 명령에서 어셈블러는 명령의 피연산자로 값을 사용하여 기호 MAXLEN을 SYMTAB에서 검색한다. 결과로 나온 object code는 명령어의 원본 버전과 정확히 동일하다. 즉 기호 대신 값을 사용하는 것이다. 그리고 statement는 더욱 이해하기 쉽다. 또한 이것이 여러 곳에서 사용되었고 이를 수정해야 할 때, MAXLEN의 값을 바꾸는 것이 symbol definition을 사용하지 않았을 때보다 훨씬 간단하다. 변수의 장점과 거의 동일한 것 같다.
EQU의 또 다른 일반적인 사용 용도는 레지스터의 mnemonic 이름을 정의하는 것이다. SIC같은 범용 레지스터(S, T)가 많은 기계에서는 레지스터에 대한 mnemonic 이름을 사용하는 것이 도움이 될 수 있다(SIC에서 레지스터의 표준 mnemonic은 이미 SIC에 정의되어 있음). fig 4와 같이, 프로그래머는 프로그램에서 레지스터의 논리적 기능을 반영하는 이름을 설정하고 사용할 수 있다.

Restrction in Symbol Definitions
물론 Symbol Definitions에는 제한도 있다. 구문의 오른쪽에 사용된 모든 기호(= 새 기호의 값을 지정하기 위해 사용되는 모든 용어)는 프로그램에 이전에 정의되어 있어야한다. 예시를 보자.
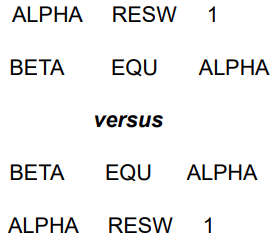
위의 두줄은 EQU에 오른쪽 기호 ALPHA가 이미 위에 정의되었다. 때문에 BETA를 ALPHA의 Symbol Definitions로 사용할 수 있다. 반변에 밑의 두줄은 ALPHA가 정의되기 이전에 EQU 구문이 존재한다. 이때는 오류가 발생하게 되는 것이다. 왜냐하면 모든 기호들은 PASS 1에서 정의되기 때문이다.
Expression
이번에는 Expression(수식)를 알아보자. 대부분의 어셈블러는 단일 피연산자(레이블, 리터럴 등)가 허용되는 곳이면 어디서나 수식을 사용할 수 있어야 한다. 물론 이러한 각 수식은 단일 피연산자 주소 또는 값을 생성하기 위해 어셈블러에 의해 평가되어야 한다.
어셈블러는 일반적으로 연산자 +,-,*,/를 사용하여 정규 규칙에 따라 형성된 산술식을 허용한다.
표현식의 개별 항은 상수, 사용자 정의 기호, 특수 항일 수 있다. 가장 일반적인 특수항은 위치 카운터(locational counter)의 현재값(일반적으로 *로 지정됨)이다. 이 항은 할당되지 않은 다음 메모리 위치의 값을 나타낸다.
- Ex) Line 106 in fig 1: BUFEND EQU *
이 구문은 버퍼 영역 이후의 다음 바이트 주소 값을 BUFEND에 제공한다.
수식은 산출되는 값의 유형에 따라 분류된다.
- Absolute expressions: 프로그램 위치와 무관
- Relative expressions: 프로그램 시작위치와 연관
EQU에 의해 정의된 기호는 절대적이거나 상대적일 수 있다는 것이다. 예시를 확인해보자.
- 107 1000 MAXLEN EQU BUFEND-BUFFER
헷갈리지 말자. 저기서 16진수 1000은 Loc 열의 다른 대부분의 항목과는 다르게 주소를 나타내지 않는다. 이는 소스 코드에 나타나는 기호와 연관된 값(여기서는 BUFEND-BUFFER=1000)을 표시한다. S를 프로그램의 시작 주소라고 한다면 (BUFEND+S)-(BUFFER+S)로 표현할 수 있고 결국에 시작 주소에 대한 정보는 없어지므로 이는 absolute expressions다.
수식의 유형을 결정하려면 프로그램에 정의된 모든 기호의 유형을 추적해야 한다. 이를 위해 SYMTAB에 값 자체 외에도 값의 유형(절대or상대)을 나타내느 플래그가 필요하다. 따라서 SYMTAB는 절대/상대 기호를 구별하는 type field가 필요하다.
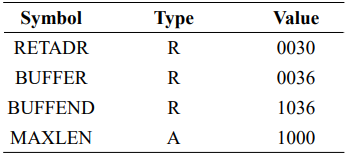
피연산자는 재배치를 위한 상대적인 값을 가질 수 있으므로 이는 이후에 로더에 의해 수정되어야한다.
Program Block
이번에는 네번째 특징인 Program Block이다. 이전 특징들보다는 좀 복잡한 개념인 것 같다. 지금까지 우리가 본 모든 예시에서의 프로그램은 하나의 단위로 취급되었다. 소스 프로그램에는 논리적으로 서브루틴(subroutine), 데이터 영역이 포함되었다. 그러나 어셈블러가 하나의 독립체(entity)로 처리하여 object code의 단일 블록이 생성되었다.
많은 어셈블러가 소스 및 object program을 보다 유연하게 처리할 수 있는 기능을 제공한다. 일부 기능을 사용하면 생성된 machine instructions와 데이터가 해당 소스 코드와 다른 순서로 object program에 나타날 수 있다. program blocks은 단일 object program 유닛 내에서 재배열된 코드의 세그먼트를 말한다.
다른 기능으로는 object program의 몇 가지 독립적인 부분이 만들어진다. 이러한 부분들은 각자의 독립성을 유지하며 로더에 의해 별도로 처리된다. 이는 control sections인데 독립된 object program 유닛으로 변환된 세그먼트를 말한다. 이는 뒤에서 자세히 다룰 것이다.
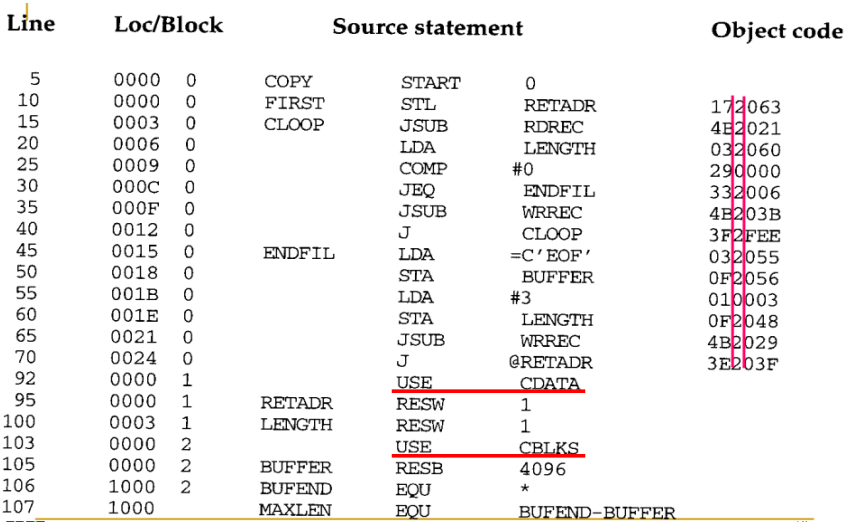

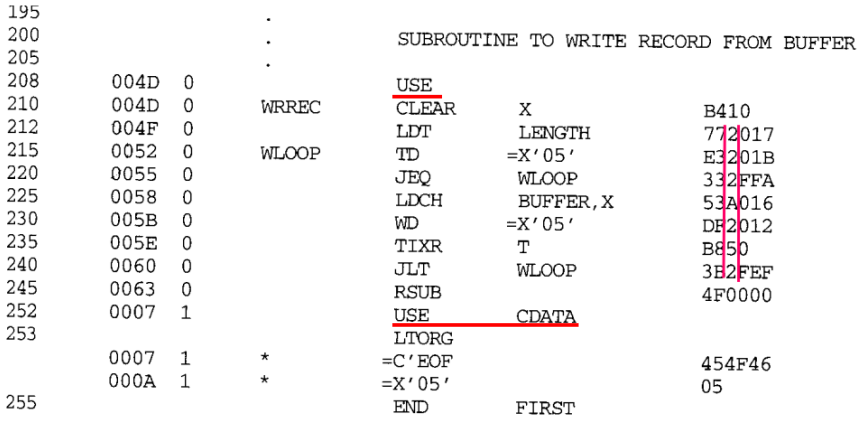
fig 7은 프로그램 블록을 사용하여 작성할 수 있는 예제 프로그램이다. 어셈블러 directives USE는 소스 프로그램의 어느 부분이 어떤 블록에 속하는지 표시한다. 만약 USE 구문이 포함되지 않은 경우, 전체 프로그램은 단일 블록에 속한다. 여기서는 3가지 프로그램 블록을 사용한다.
- 실행 instructions: 이름 없음
- 길이가 몇 words 이하인 데이터 영역: CDATA
- 대용량 메모리 블록으로 구성된 데이터 영역: CBLKS
각 프로그램 블록에는 상대 주소 공간이 별도로 존재한다.
Pass 1에서는 각 프로그램 블록에 대해 별도의 LOCCTR을 유지한다. 각 레이블은 해당 레이블이 포함된 블록의 시작 부분에 상대적인 주소를 할당받는다. 그리고 SYMTBL은 각 기호에 대한 블록 번호를 저장한다. 그리고 Block Table에 각 블록의 시작 주소를 저장한다. 이후 Pass 1이 끝나면, 어셈블러는 fig 8처럼 모든 블록의 시작주소와 길이를 포함하는 표를 만든다.

Pass 2에서는 번환을 위해 어셈블러가 object program의 시작에 비례하여 각 symbol의 주소를 계산한다. 즉, 할당된 블록 시작주소에 블록 시작에 비례하여 기호의 주소를 추가한다.
이렇게 되면 어셈블리 코드의 순서와는 다르게 object code는 각 (default)-CDATA-CBLKS 순서로 배열된다.
Advantages of Using Program blocks
어떤 이점이 있길래 이런 기능을 사용하는 걸까? 바로 모순되는 목표를 이루기 위해서이다.
우선 특정 순서에 따라 프로그램을 블록으로 구분하게 된다. 여기서는 큰 버퍼 영역(4096-byte)이 object program의 맨 끝으로 이동하게 된다. 이 영역이 프로그램의 사이에 위치한다면 해당 영역 앞과 뒤에 위치한 구문들이 멀리 위치하게 된다. 이 말은 결국 extended format, base-relative를 더욱 빈번하게 사용한다는 뜻이다. 하지만 버퍼 영역을 끝에 위치시킴으로써 이런 경우를 줄일 수 있다. 그리고 리터럴 풀을 배치하는 것이 더 쉽다. 리터럴을 CBLKS 앞의 CDATA 블록에 넣기만 하면 된다.
그리고 데이터 영역이 흩어져 있다. 이 말은 데이터 영역이 이것을 참조하는 구문에 가까이 있을 수록 가독성이 높아진다는 것이다.
즉 여기서 말하는 program blocks가 가능하게 하는 모순되는 목표는 소스 코드에서는 데이터 영역을 흩어지게 하여 가독성을 높이면서 object code에서는 데이터 영역을 한 곳에 모아 프로그램의 성능을 높이는 것이다.
이미지 출처
- “Computer Organization and Design (5th Edition)” by Patterson & Hennessy]
'시스템 프로그래밍' 카테고리의 다른 글
| Linkers and Loaders (0) | 2021.11.01 |
|---|---|
| Assemblers (4) (0) | 2021.10.15 |
| Assemblers (2) (0) | 2021.10.14 |
| Assemblers (1) (0) | 2021.09.28 |
| SIC/XE (SIC/eXtra Equipment) (0) | 2021.09.12 |




댓글