SIC/XE에 관해 이전까지 알아보았다. 알아봤듯이 컴퓨터는 기계어(0과 1로만 구성된) 명령을 들으면 그것을 수행한다. 하지만 우리는 c나 python같은 언어로 코드를 작성하여 프로그램을 만든다. 그러므로 당연히 이러한 코드를 기계어로 변환하는 과정이 필요한 것이다. 그러한 역할을 하는 프로그램 중 이번에는 Assember(어셈블러)에 대해 알아볼 것이다.
Translating and Starting a Program
컴퓨터가 처음 나왔을 때는 프로그래머들은 기계어로 컴퓨터를 제어했다(처음에는 그 이외의 방법은 존재하지 않았으니깐). 하지만 위에서 설명했듯이 기계어는 기계가 이해하기에는 매우 좋지만 사람이 이해하기는 너무나도 어렵다. 때문에 지금은 프로그램을 프로그래밍 언어로 작성하고 이것을 기계어로 번역한다. 추가로 덧붙이자면 사람이 이해하기 쉬울수록 고급언어(high-level language)에 가깝고, 기계가 이해하기 쉬울수록 저급언어(low-level language)에 가깝다.
Translation Hierarchy
고급언어로 작성된 프로그램이 컴퓨터에서 동작하는 프로그램으로 변화하기까지 일반적으로 4개의 단계를 밟는다. 몇몇 단계에서는 각 단계들이 결합하기도 하고 번역시간을 줄이기 위해 건너뛰기도 한다. 이 때 4개의 프로그램이 사용되는데 compiler, assembler, linker, loader가 그것들이다.
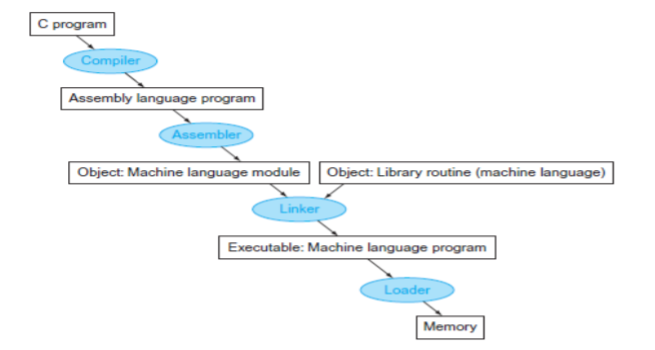
c언어로 작성한 프로그램이 있다고 하자. compiler는 c언어로 작성된 프로그램을 어셈블리어로 이루어진 프로그램으로 변역한다. 그리고 assembler는 이것을 읽고 기계어로 이루어진 Object를 생성한다(ex. .o확장자를 가진 파일). 이것들을 linker가 받아서 실행가능한 파일(ex. .exe 파일)로 만든다. 이것을 실행하게 되면 loader가 메모리로 프로그램을 이동시켜서 프로그램이 동작하게 되는 것이다.
What is "Assembler"?
위에서 설명한 4가지 프로그램 중에서 이번에는 assembler에 집중해보자. 다시 설명하자면 어셈블러는 SW인데 어셈블리어로 작성된 코드를 기계어로 된 코드(ex. object file, .o, ...)로 변환한다. 어셈블리어는 기계가 이해하는 것에 대한 기호적 표현이다. 우리가 흔히 쓰는 프로그래밍 언어와 기계어의 중간 단계라고 보면된다(01000111... 이런거 보다는 훨씬 이해하기 쉽다). 오브젝트 파일은 명령어를 적절히 메모리에 배치하는데 필요한 기계어 명령, 데이터, 정보들의 조합이다.
어셈블러가 수행해야 하는 기본기능들을 살펴보자. 우선 mnemonic 연산 코드(어셈블리어로 생각하자)를 그에 동등한 기계어로 변환해야 한다. 그리고 프로그래머가 사용하는 symbol lables(기호 레이블)(변수, 함수, ...)에 기계 주소를 할당해야 한다. 다시 말해, 어셈블리 언어 프로그램에서 각 명령어를 이진수로 표현하기 위해서는 어셈블러가 모든 레이블에 해당하는 주소를 결정해야 한다. 어셈블러는 symbol table을 사용하여 명령에 사용된 레이블을 추적하는데 symbol table은 레이블의 이름과 그것이 위치한 memory word의 주소를 매칭해놓은 table이다.
Assembler & Its Machine Dependency
만약 윗 파트에서 설명한 어셈블러의 기본적인 기능만 고려한다면, 대부분의 어셈블러들은 매우 유사할 것이다. 그러나 어셈블러의 특징과 설계는 명령의 형식과 addressing modes같은 기계 구조의 크게 의존한다.
우선 SIC 표준 버전의 기본 어셈블러 설계를 살펴보도록 하자.
SIC Assembler Language Program
SIC 버전의 어셈블러를 살펴보기 위해 예시 코드를 이용할 것이다. 그전에 몇가지 정리하고 넘어가자.
- 행의 번호는 참조용이며 프로그램의 일부가 아니다.
- 사용되는 mnemonic 명령은 이전에 설명한 instruction set을 참고하자.
- indexed addressing은 피연산자 뒤에 'X'라는 수식어를 붙여서 나타낸다(160번째 행 참고)
- '.'으로 시작하는 행은 주석이다.
- mnemonic machine instructions 외에도 다음과 같은 assembler directives가 사용된다.
- START: 프로그램의 이름과 시작 주소 지정
- END: 소스 프로그램의 끝을 표시하고 (선택적으로) 프로그램에서 첫번째로 실행가능한 명령문을 명시한다.
- BYTE: 문자나 16진수 상수 생성또는 constant를 나타내는데 필요한 만큼의 byte 공간을 차지하는데 사용된다.
- WORD: one-word 정수 상수를 생성한다.
- RESB: 데이터 영역에 지정한 바이트 수 만큼 공간을 예약한다.
- RESW: 데이터 영역에 지정한 word 수 만큼 공간을 예약한다.
- Directives는 기계어 명령으로 변역되지 않는대신 스스로 어셈블러에게 명령들을 제공한다.
- 예시 프로그램은 입력 장치(장치 코드: F1)에서 레코드를 읽고 출력 장치(코드: 05)로 복사하는 main routine이 포함되어 있다.
- main routine은 두 개의 subroutine을 호출한다.
- RDREC: 레코드를 읽어서 버퍼(=4096 bytes)로 옮긴다.
- WRREC: 버퍼에서 출력장치로 레코드를 쓴다.
- 사용 가능한 I/O 명령은 RD와 WD뿐이기에 각 subroutine은 한 번에 하나의 문자를 전송해야 한다.
- 각 레코드는 여러 개의 문자로 구성된다.
- 각 레코드의 끝에는 null 문자(16진수로는 00)가 표시된다.
- 입력 장치와 출력 장치 간 I/O 속도가 다르기 때문에 버퍼를 필요로 한다.
- 파일의 끝이 감지되면 프로그램은 출력 장치에 EOF(End of File)을 쓰고 RSUB 명령을 실행함으로써 종료된다.
- OS에서 JSUB 명령을 사용하여 프로그램을 호출했다고 가정한다.
- 따라서 RSUB는 다시 OS에게 제어권을 준다.
마지막 부분에 설명을 더하자면, OS가 명령을 계속 읽고 있다가 'JSUB COPY'라는 명령어를 만나면 (다음 명령어 주소는 10이라고 하자), register L에 주소값 10을 복사해놓고 PC(컴퓨터 PC 아님!!)값이 COPY 프로그램이 위치한 주소로 바뀐다. 이후 프로그램이 RSUB를 만나 종료되면 register L에 있는 값을 다시 PC register에 복사하고 다시 OS로 돌아와 'JSUB COPY'이후 명령어를 처리한다.
설명만으로는 감이 안잡힌다...ㅠㅠ 이제 직접 예시를 이해하면서 익숙해져보자.
fig 2-1. SIC Assembler Language Program
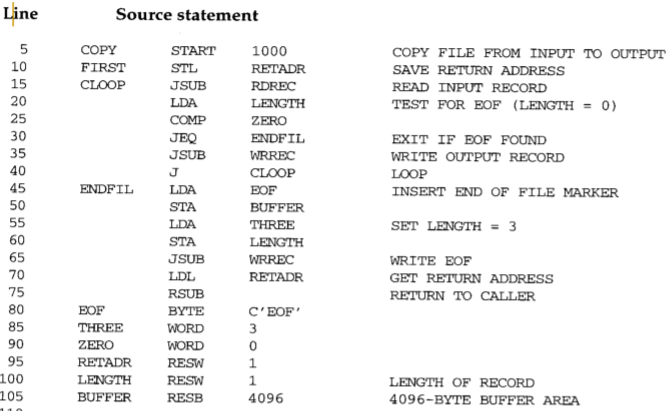

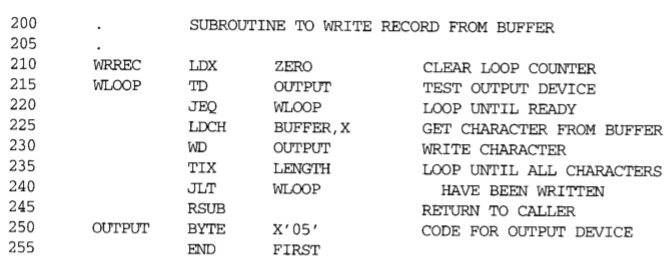
3부분으로 구분이 되는게 보이는가? 확실히 c같은 프로그래밍 언어보다 가독성이 떨어진다... 그래도 주석으로 설명도 되있으니 조심스레 살펴보자✊
Main routine
첫번째 파트는 main routine이라고 보면 되겠다. 참고로 routine의 밑부분은(여기서는 80~105) 프로그래머가 사용하고자 하는 공간에 이름을 붙여 예약하는 곳이다. 이에 대한건 위에서 설명했다. 변수나 상수를 선언하는 것과 유사하다. COPY 레이블은 'START 1000' 한 줄로 이루어져 있다. 즉 프로그램 이름으로 COPY, 시작주소로는 1000을 지정했다.
'FIRST STL RETADR'에서는 COPY로 넘어오기전 OS의 return address를 register L에 저장했는데 이를 RETADR이라는 변수에 저장한 것이다. 이렇게 해준 이유는 register L은 subroutine으로 이동할 때 다른 값으로 덮어져서 OS의 return address를 다른 곳에 저장할 필요가 있기 때문이다. 이렇게 해주면 해당 프로그램이 끝나고 os에게 다시 control flow를 넘길 수 있다.
CLOOP 레이블(15~40)에서는 subroutine RDREC을 호출한 다음 WRREC을 호출하는 것을 반복하면서 레코드를 읽고 이를 출력장치에 쓴다. 그리고 LENGTH가 0이 되면 ENDFIL 레이블로 jump한다.
ENDFIL 레이블(45~75)에서는 출력장치에 문자열 'EOF'를 쓰면서 프로그램을 종료한다. 버퍼에 'EOF'를 실은 다음 LENGTH를 3으로 바꿔서 'EOF' 3글자를 WRREC을 이용해 출력장치에 쓴다. 그리고 RETADR에 있는 값을 register L에 덮어쓴 다음 RSUB을 이용해 OS에게 제어권을 넘겨준다.
Subroutine RDREC
RDREC을 호출하여 해당 subroutine으로 넘어오면 (125~130) 우선 register X, A의 값을 0으로 초기화해준다.
그리고 RLOOP 레이블(135~170)에서는 TD로 입력장치를 테스트 한 다음 이상이 있으면 다시 RLOOP 레이블로 돌아가고 이상이 없으면 RD로 입력장치에 있는 데이터를 register A로 옮긴다. 이때 register A의 값이 0(= null)이라면 EXIT 레이블로 jump하고 그렇지 않으면 register A의 값을 버퍼의 X index(indexed addressing)에 저장한다. 그리고 TIX로 X의 값을 1늘리고 이를 버퍼의 최대크기와 비교하여 버퍼가 가득 찼는지 여부를 판단한다. 아직 buffer 공간이 남아있다면 RLOOP로 다시 이동하고 그렇지 않다면 다음 줄인 EXIT 레이블로 이동한다.
EXIT(175~180)에서는 X(마지막으로 저장한 버퍼의 위치)값을 LENGTH라는 변수에 저장한 다음 RSUB로 해당 routine을 빠져나온다.
Subroutine WRREC
WRREC을 호줄하여 jump하게되면(210) 우선 register X의 값을 0으로 초기화한다.
그리고 WROOP 레이블(215~245)은 데이터 이동 방향이 반대지만 RDREC의 RLOOP와 매우 유사하다. 출력장치를 검사하고 버퍼의 X번째 index의 값을 A register로 옮긴다음 출력장치에 그것을 쓴다. 그 다음 'TIX LENGTH'를 이용하여 써야할 내용이 버퍼에 더 남아있는지 판단한다. 그렇다면 WLOOP 레이블로 다시 돌아가고 그렇지 않다면 RSUB을 이용해 해당 루틴을 빠져나온다.
그리고 마지막줄(255)에서 'END FIRST'를 써주어 해당 소스 코드의 끝을 표시하고 FIRST 레이블을 명시한다.
fig 2-2. fig 2-1 with Object Code
이번에는 위의 프로그램이 object code로 변환된 그림을 살펴볼 것이다. 여기서도 살펴보기 전에 몇가지를 알아보고 넘어가자.
'Loc'열이 추가되는데 이는 assembled program의 각 부분에 대한 machine address(16진수)를 제공한다. 여기서는 1000번 주소에서 프로그램이 시작된다고 가정하자.
그리고 soucre program을 object code로 변환하기 위해서는 몇몇 기능이 필요하다.
- mnemonic operation codes를 동등한 기계어로 변환한다. 예를 들어 fig 2.1 10번 라인의 STL은 14로 변환된다.
- symbolic operands를 동등한 기계어로 변환한다. 예를 들어 fig 2.1 10번 라인의 RETADR은 1033으로 변환된다.
- 적절한 형식으로 기계어 명령을 빌드한다.
- source program에 지정된 data constants를 내부 기계어 표현으로 변환한다. 예를 들어 fig 2.1 80번 라인의 "EOF"는 '454F46으로 변환될 수 있다.
- object program과 assembly listing file을 쓴다. 뒤에 나올 fig 2.3는 object program을 보여주고 fig 2.2는 assembly listing과 비슷하다. assembly listing file은 어떻게 프로그램이 변환되었는지 확인하는데 쓰인다.
위의 기능들은 한 번에 한 줄씩 source program의 순차적인 처리를 통해 쉽게 수행이 가능하다. 그러나 주소를 번역하는 '2.'기능은 문제를 야기한다. 'Loc:1000인 fig 3 10번 라인의 instruction에서 RETADR은 1033으로 변환된다.' 부분을 예로 들면 프로그램은 순차적으로 처리되는데 RETADR은 Loc:1033에서 정의되기 때문에 RETADR이 무엇을 뜻하는지 알 수가 없다. 때문에 대부분의 어셈블러는 2개의 pass를 source program위에 만든다.
- 1st pass는 source program에서 lable 정의를 스캔하는 동시에 레이블에 주소를 할당한다.
- 2nd pass는 위에서 설명한 실제 변환의 대부분을 수행한다.
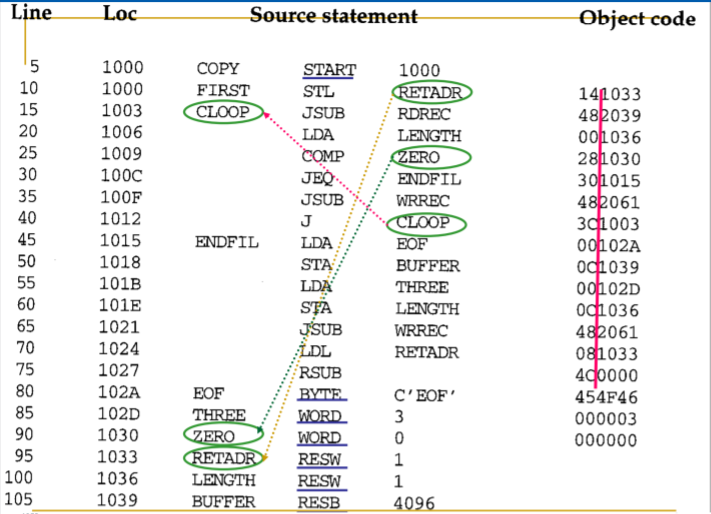
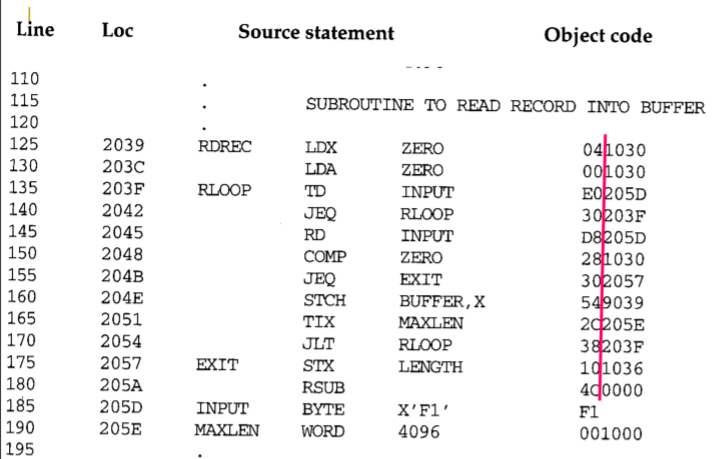

주요한 부분을 살펴보자. 우선 어떻게 기계어로 변환되는지 Loc:1000의 'FIRST STL RETADR'을 예로 들어보자. 우선 SIC의 instruction format은 24-bit(3bytes)인 것을 기억하는가? 이중 8bits는 opcode정보를, 1bits에는 indexed addressing 사용 여부를, 나머지 15bits에는 주소 정보를 담는다고 했다. 그러므로 object code '141033(0001 0100 0001 0000 0011 0011)'에서 앞의 '14'는 STL이라는 opcode를 의미하고 뒤의 '1033'은 indexed addressing을 사용하지 않으며 Loc:1033에서 할당된 공간을 뜻한다. 그래서 기계가 '141033'을 읽으면 '1033 주소 공간에 STL이라는 작업을 수행하면 되겠구나'라고 이해하는 것이다.
그리고 Loc가 어떻게 증가하는지 살펴보자. 일반적으로는 3씩 증가한다. 그도 그럴게 대부분의 instruction은 3bytes(1word)로 구성되기 때문이다(SIC의 메모리 구조에 대해 기억해보자). 그런데 line 185를 보면 Loc 값이 1만 증가하는 것을 확인할 수 있다. 이는 해당 공간에 1 byte크기의 공간을 할당하고 거기에 16진수 'F1'을 넣었기 때문이다.
마지막으로 이 프로그램의 전체 크기는 어떻게 될까? 이는 Loc의 마지막 값과 시작 값을 빼고 거기에 1을 더하면 간단히 알 수 있다. 여기서는 2079 - 1000 + 1 = 107A이므로 프로그램의 크기는 107A bytes임을 알 수 있다. '왜 마지막에 1을 더하지?'라는 의문을 가질 수 있는데 마지막 Loc:2079의 object code인 '05'(1byte)도 더해야 하기 때문이다.
fig 2-3 Object Program corresponding to fig 2-2
어셈블러는 생성된 object code를 storage같은 일부 출력장치에 기록해야 한다. 저장된 이 object code는 나중에 실행을 위해 memory에 로드된다.
간단한 object program format에는 3가지 type의 레코드가 포함된다.
- Header record: 프로그램의 이름, 시작 주소 및 길이가 담김
- Col. 1: H
- Col. 2-7: Program name
- Col. 8-13: object program의 시작주소(16진수)
- Col. 14-19: bytes로 표현한 object program의 길이(16진수)
- Text record: 변환된 instruction과 data가 담겨있으며, 이 instruction과 data가 로드될 주소 표시도 포함되어 있다.
- Col. 1: T
- Col. 2-7: 해당 레코드의 object code 시작주소(16진수)
- Col. 8-9: bytes로 표현한 해당 레코드의 object code 길이(16진수)
- Col. 10-69: 16진수로 표현된 object code(column 2개가 1 byte)
- End record: object program의 끝을 표시하고 program이 시작될 때 주소를 지정한다.
- Col. 1: E
- Col. 2-7: object program에서 첫 번째 실행 가능한 주소(16진수)

이 코드를 보면(실제로 하나씩 변환한 사람은 없겠지만) 1033-2038 영역, 즉 'RESW'나 'RESB'로 만들어진 영역에 해당하는 object code는 없는 것을 확인할 수 있다. 이러한 directives로 만들어지는 메모리 공간의 값들은 'BYTE'나 'WORD'와 달리 프로그램이 동작하면서 결정되므로 assembler가 해당하는 object code를 정의할 수 없는 것이다. 때문에 이 영역은 Loader에 의해 공간이 예약이 되고 프로그램이 이 공간을 사용할 수 있게된다.
The Object File for UNIX
UNIX 시스템용 object file은 일반적으로 서로 다른 6개의 조각으로 나눠볼 수 있다.

- Header: object file의 나머지 5개 조각의 크기와 위치를 설명한다.
- Text Segment: 기계어 코드가 담겨있다.
- Static Data Segment: 프로그램이 살아있는 동안 할당되는 데이터를 담고 있다.
- UNIX를 사용하면 static data(프로그램 전체에 할당)와 dynamic data(프로그램에 의해 필요에 따라 증가하거나 감소할 수 있음)을 모두 사용할 수 있다.
- Relocation Information: program이 메모리에 로드될 때 절대 주소에 따라 달라지는 instructions 및 data words 식별
- Symbol Table: fuctions 및 전역 변수에 대한 <lable-address> 정보를 담고 있다.
- Debugging Information: machine instruction을 C source files과 연결할 수 있도록 symbolic 정보를 포함한다.
2-pass Assembler
위에서 어셈블러는 2개의 pass를 가진다고 설명했다. 이에 대해 더 자세히 살펴보자.
Pass 1: Define Symbols
- assembly code의 statement를 읽는다.
- 위치카운터 LOCCTR을 이용하여 N(word addressing or byte addressing)으로 주소를 증가시키면서 해당 statement에 주소를 할당한다.
- pass 2에서 사용할 수 있도록 모든 레이블에 할당된 주소 값 symbol table에 저장
- 상수 선언, 공간 예약같은 assembler directives의 처리를 수행한다.
- BYTE, RESW 등으로 정의된 데이터 영역의 길이 결정 같은 주소 할당에 영향을 미치는 처리가 이에 해당한다.
Pass 1은 일반적으로 할당된 주소, 오류 표시 등과 함께 각 source statement를 포함하는 intermediate file을 작성한다.
Pass 2: Assemble instructions & generate object program
- 코드 한 줄을 읽는다. 이때 pass 1이 작성한 intermediate file은 pass 2의 입력으로 사용된다.
- OP Code Table을 이용하여 operation code를 변환한다.
- Symbol Table을 이용하여 레이블을 주소로 변환한다.
- pass 1에서 끝내지 못한 assembler directives의 처리를 수행한다.
- objet program을 생성한다.
2 Data Structures of SIC Assembler
Operational Code Table (OPTAB)
ADD, STL, COMP, ...등으로 opcode를 표현하는데 어셈블러가 이것을 읽고 'ADD는 더하기 연산이고 기계어로 변환하면 ~구나!'라고 인식을 해야하기에 이러한 정보를 모아놓은 OPTAB이 필요하다.
- mnemonic op code와 그에 해당하는 machine language를 담는다. 만약 더 복잡한 어셈블러라면 가변 크기나 형식을 가지는 instruction을 포함할 수 있다.
- pass1에서는, mnemonic code를 조회하고 검증하는데 사용된다.
- pass2에서는, op codes를 기계어로 변환하는데 사용된다.
- 보통 hash table로 구성하여 최소한의 탐색으로 빠르게 탐색한다. 그리고 key로 mnemonic code가 쓰이고 일단 OPTAB은 준비가 되면 이후에 수정되지 않는다.
Symbol Table (SYMTAB)
'FIRST STL RETADR'이라는 구문을 pass1에서 읽어서 'RETADR이 1033에 위치하는구나!'라고 인식하고 이후 pass2에서 해당구문을 읽고 '기계어로 변환할 때 address field에는 1033을 넣어야하는 구나!'라고 인식하게 해야한다. 때문에 각 레이블에 대한 정보를 담고 있는 SYMTAB가 필요하다.
- source program의 각 lable에 대한 이름과 값(주소), flag(오류 조건)가 담긴다. 또한 종류나 길이같은 기타 정보를 포함할 수 있다.
- pass1에서는, lables가 (LOCCTR에서 할당된)주소와 함께 SYMTAB에 입력된다.
- pass2에서는 피연산자로 사용되는 symbols를 SYMTAB에서 찾아 assembled insturuction에 삽입할 주소를 얻는다.
- 효율적인 추가와 탐색이 필요하기 때문에 hash table 사용
자료 출처
- Adam Hoover, “System Programming with C and Unix, Addison Wesley 2010.
- Abraham Silberschatz, Peter Baer Galvin, and Greg Gagne, “Operating System Concepts (10th Edition), Wiley 2019
'시스템 프로그래밍' 카테고리의 다른 글
| Assemblers (4) (0) | 2021.10.15 |
|---|---|
| Assemblers (3) (0) | 2021.10.15 |
| Assemblers (2) (0) | 2021.10.14 |
| SIC/XE (SIC/eXtra Equipment) (0) | 2021.09.12 |
| SIC (Simplified Instructional Computer) (0) | 2021.09.09 |




댓글