이번에 알아볼 것은 프로세스와 쓰레드에 관한 것이다. 다음과 같은 것들을 살펴볼 것이다.
- 프로세스
- 개념
- 프로세스의 표현
- Context Switch
- 동작 및 관련 시스템콜: fork(), exec(), wati(), ...
- 쓰레드
- 정의
- 싱글 쓰레드 vs. 멀티 스레드
- 멀티 쓰레딩 모델들
- 리눅스의 쓰레드
우선 OS는 프로세스 관리와 관련하여 다음 활동을 담당한다. 마지막 두 개는 이 수업에서 다루지 않는다.
- 사용자 및 시스템 프로세스 생성 및 삭제
- 프로세스 중단 및 재개
- 프로세스 통신을 위한 메커니즘 제공(IPC)
- 프로세스 통신을 위한 메커니즘 제공
- 교착 상태(dedlock) 처리를 위한 메커니즘 제공
Process
그럼 우선 프로세스가 무엇인가에 대해서 우선 이해해보자. 이전 글에서 잠깐 말했었는데 프로세스는 (현재)실행중인 프로그램을 뜻한다. 조금 더 일반적으로 말하면 실행될 다음 명령어와 관련 리소스 집합을 지정하는 PC(Program Counter)가 있는 활성 개체이다. 반면에 프로그램은 디스크에 저장된 파일의 내용과 같은 수동적 개체이다.

The Memory Layout of a Process
보조 저장 장치에 프로그램이 있고 이를 실행하게 되면 메모리에 영역이 할당되어 프로그램이 실행되고 이를 프로세스라고 했었다. 프로세스가 위치한 메모리 영역은 어떤 레이아웃을 가지는지 알아보자.
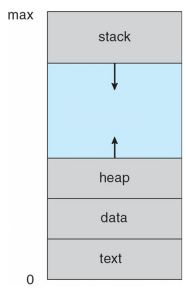
일반적으로 여러 섹션으로 나뉜다. 우선 텍스트 섹션은 실행 코드를 포함하고 있고, 데이터 섹션은 전역 변수를 포함하고 있다. 이 두 섹션의 크기는 프로그램 실행 중에 변경되지 않고 고정된다. 당연하다 이 둘의 내용은 이후에 수정될게 없으니깐 말이다.
반면에 다음 두 섹션인 힙, 스택 섹션은 프로그램 실행 중에 동적으로 줄어들거나 커질 수 있다. 이때 OS는 두 영역이 서로 겹치지 않도록 해야한다.
스택 섹션은 함수 호출 시 함수의 매개변수, 지역 변수 및 반환 주소가 포함된 활성화 레코드가 스택에 push된다. 이후 함수에서 control이 반환되면 활성화 레코드가 스택에서 pop된다. 힙 섹션은 메모리가 동적으로 할당됨에 따라 커지고(ex. 런타임 도중 malloc에 의해 메모리 할당) 메모리가 시스템으로 반환되면 축소된다.
Memory Layout of a C Program
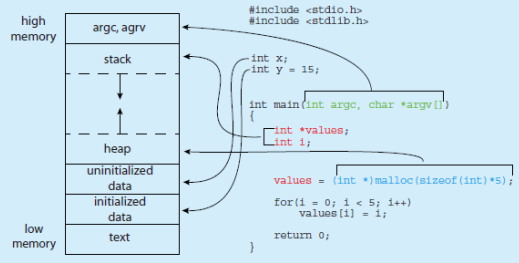
C program에서의 메모리 레이아웃을 알아보자. 우선 데이터 섹션은 전연 변수 초기화 여부에 따라 두개의 다른 영역(uninitialized/initialized)으로 나뉜다. 그리고 main() 함수에 전달된 argc 및 argv 매개변수에 대한 별도의 영역도 제공된다.

그리고 GNU의 'size'라는 커맨드가 있는데 fig 1.2와 같은 결과를 출력한다. text는 텍스트 섹션의 크기, data는 uninitialized data의 크기, bss는 initialized data의 크기이다. dec과 hex는 이 3영역 크기의 합이다. 스택과 힙 영역에 대한 크기는 실행할 때마다 달라지기 때문에 당연히 표시되지 않는다.
Program vs. Process
위에서 잠깐 언급했던 프로그램과 프로세스의 차이에 대해 더 알아보자. 프로그램 자체는 프로세스가 아니다. 실행 파일이 메모리에 로드될 때 프로세스가 된다고 했다. 프로그램을 실행한다는 것은 실행 파일 아이콘을 더블 클릭하거나 실행 파일 이름을 커맨더 라인에 입력하는 것이다.
동일한 프로그램으로 여러 프로세스가 만들어질 수 있지만 그럼에도 불구하고 이것들은 별도의 실행 시퀀스로 간주된다. 이들의 텍스트 섹션은 동일하지만 데이터/힙/스택 섹션은 다르다.
Process State
프로세스는 어떠한 '상태'를 가진다. 어떠한 상태들을 가질 수 있을까? 우선 프로세스가 실행되면 '상태'가 변경되고 다음 중 하나가 될 수 있다.
- new: 프로세스 생성 중
- ready: 프로세스가 프로세서에 할당되기를 기다림
- running: 명령이 실행 중이다. 모든 프로세서 코어에서 한 번에 하나의 프로세스만 실행할수 있다. 때문에 많은 프로세스가 준비되어 대기 중일 수 있다.
- waiting: 프로세스가 어떤 이벤트(ex. I/O 완료나 신호 수신)가 발생하기를 기다리고 있다.
- terminated: 프로세스가 실행을 완료함.
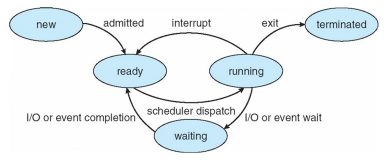
ready queue라는 것이 있는데 이 곳에서 프로세서에 할당되기를 기다리는 ready 상태의 프로세스들이 있다. 스케줄러가 맨 앞의 프로세스를 pop하면 cpu가 해당 프로세스를 처리한다. 그러다가 timer가 만료되거나 I/O event를 기다린다음 완료되면 ready queue로 다시 push된다. 여기서 waiting 상태에서도 프로세스들이 디바이스에 따라 wating queue라는 곳에 위치하게 되는데 I/O 작업이 완료되거나 하면 다시 ready queue로 이동한다.
Process Representation (in Linux)

각 프로세스는 OS에서 작업 제어 블록(Task Control Block)이라고도 하는 프로세스 제어 블록(PCB, Process Control Block)으로 표현된다. 간단히 말해서 일부 accounting 데이터와 함께 프로세스를 시작하거나 다시 시작하는데 필요한 모든 데이터의 저장소 역할을 한다. 따라서 특정 프로세스와 관련된 많은 정보를 포함한다.
- Process state
- Program counter: 이 프로세스에 대해 실행될 다음 명령어의 주소
- CPU register: 모든 process-centric 레지스터의 내용
- CPU Scheduling information: 프로세스 우선순위, 스케줄링 큐 포인터 및 기타 스케줄링 매개변수
- Memory Management information: 프로세스에 할당된 메모리
- Accounting info: CPU 사용량, 시작 이후 경과된 시간, 시간 제한 등
- I/O status information: 처리에 할당된 I/O 장치 목록, 열려 있는 파일 목록

리눅스에서는 그러한 정보들이 task_structure라는 fig 1.6 형태의 구조체에 담긴다. 여기서 *parent와 chiledren이라는 멤버 변수가 있는데 기본적으로 프로세스는 fork() 함수를 이용하여 다른 프로세스를 생성할 수 있다. 이때 생성하는 프로세스를 parent 프로세스라고 하고, 생성되는 프로세스를 child 프로세스라고 한다. 이러한 관계가 저 두 변수를 통해 정의되는 것이다.

그리고 리눅스에서는 PCB들이 양방향 연결리스트 형태로 관리되고 있다. 그리고 current라는 포인터를 통해 현재 실행 중인 프로세스의 PCB를 가리킨다. 이를 이용해 현재 프로세스의 정보를 수정하거나 할 수 있다.
ps
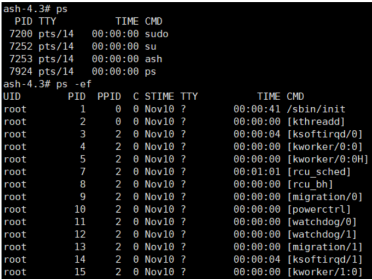
리눅스의 'ps' 명령어를 통해 현재 실행 중인 프로세스들을 확인할 수 있다. '-el', 'ef' 등의 옵션을 이용하여 시스템에서 현재 활성화된 모든 프로세스에 대한 전체 정보를 표시하거나 실행 중인 모든 프로세스나 쓰레드를 표시하게 할 수 있다.
Process Scheduling
멀티 프로그래밍의 목적은 CPU 활용을 최대화하기 위해 어떤 프로세스를 항상 실행하는 것이다. 그리고 시분할(time sharing, 멀티 태스킹)의 목적은 사용자가 실행 중인 각 프로그램과 상호작용할 수 있도록 프로세스 간에 CPU 코어를 자주 전환하는 것이다. 상기한 목표를 달성하기 위해 프로세스 스케줄러는 코어에서 프로그램 실행을 위해 사용 가능한 프로세스(사용 가능한 프로세스 집합에서)를 선택한다.
인터럽트(interrupt)는 OS가 현재 작업에서 CPU 코어를 변경하고 커널 루틴을 실행하도록 한다. 인터럽트가 발생하면 시스템은 CPU 코어에서 실행 중인 프로세스의 현재 컨텍스트를 저장해야 하다.
Context Switch
멀티 프로그래밍/태스킹에 대한 것은 저번에 설명한 적이 있었는데 문맥 교환(context switching)에 대한 것은 생소하다. 문맥(context)은 프로세스의 PCB에 표시된다. 여기는 CPU의 레지스터 값, 프로세스 상태 및 메모리 관리 정보가 포함된다. CPU가 다른 프로세스로 전환할 때 시스템은 컨텍스트 교환을 통해 이전 프로세스의 상태를 저장하고 새 프로세스에 대해 저장된 상태를 로드해야 한다.
문맥 교환 시간은 오버헤드이다. 스위칭하는 동안 시스템이 유용한 작업을 하는게 아니기 때문이다. 이러한 속도는 HW 지원에 따라 기계마다 상이하다.
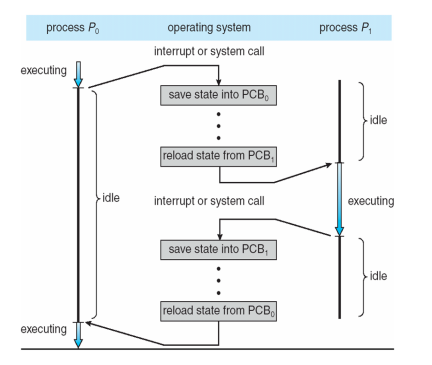
0번 프로세스가 실행하다가 인터럽트가 발생하였다. 이때 0번 PCB에 현재 상태를 저장하고 1번 PCB에 있는 데이터를 불러온 다음 1번 프로세스를 실행한다. 이 사이의 시간이 바로 문맥 교환 시간이다. 해당 시간을 줄이는 것이 오버헤드를 줄이는 것이므로 이것을 줄이는 게 중요할 것이다.
Operations on Processes
조금 전에 프로세스는 다른 프로세스를 생성하고 이들이 부모-자식 관계를 가진다고 하였다. 즉 상위 프로세스는 하위 프로세스를 형성하고, 이는 차례로 다른 프로세스를 생성하여 프로세스 트리를 형성할 수 있다. 그리고 프로세스는 일반적으로 정수 값인 프로세스 식별자(pid)를 통해 식별 및 관리된다.
init 프로세스는 모든 사용자 프로세스의 루트 상위 프로세스 역할을 한다(최근 리눅스 배포판에서는 systemd 프로세스로 변경됐다고 함). 라즈베리 파이에서는 'pstree'라는 명령어를 이용하여 프로세스 트리를 확인할 수 있다.
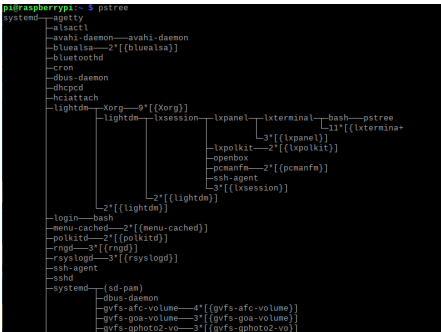
Process Creation
일반적으로 프로세스가 자식 프로세스를 생성할 때 해당 자식 프로세스는 작업을 수행하기 위해 특정 리소스(CPU time, 메모리, 파일, I/O 장치)가 필요하다. 자식 프로세스는 OS에서 직접 리소스를 얻을 수 있거나 부모 프로세스의 리소스 하위 집합을 받을 수도 있다.
부모는 자식 간에 리소스를 분할해야 하거나 여러 자식 간에 일부 리소스(ex. 메모리, 파일, ...)를 공유해 줄 수도 있다. 자식 프로세스를 부모 리소스의 하위 집합으로 제한하면 많은 자식 프로세스가 만들어졌을 때 시스템에 과부하가 걸리는 걸 방지한다.
fork()
fork() 시스템 콜은 호출한 프로세스와 동일한 새 프로세스를 생성한다. 즉 현재 실행 중인 프로그램의 복제본이다. 새로운 프로세스는 원래 프로세스의 주소 공간 복사본으로 구성되고 두 프로세스(부모, 자식) 모두 실행을 계속한다.
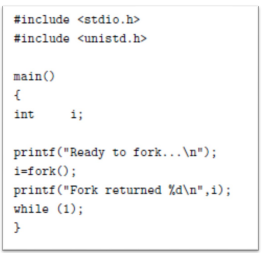
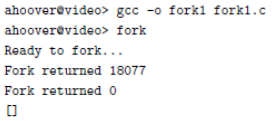
fig 1.11의 프로그램은 'fork1.c'이고 fork() 다음 무한 반복으로 들어간다. 이후 컴파일하여 fork1이라는 실행 파일을 만든 뒤 이를 실행하면 fig 1.12와 같은 정보를 출력한다. fork() 이후에 새로운 자식 프로세스가 생성되고 두 프로세스 모두 printf()를 이용해 i 값을 출력할 것이다. 이 때의 i는 서로 다른 메모리 공간에 위치하므로 서로 별개이다. 그런데 두 프로세스의 fork() 리턴값이 다른 것을 알 수 있다. 어떤 i 값이 부모 프로세스의 i 값일까?

fork()의 반환값은 자식 프로세스는 0을 반환하고 부모 프로세스는 생성된 자식 프로세스의 pid를 반환한다. 즉 fig 1.12에서는 '18077' 새롭게 생성된 자식 프로세스의 pid인 것이고 이 printf()는 부모 프로세스에서 실행된 것이다. 이를 나타내면 fig 1.13과 같다.

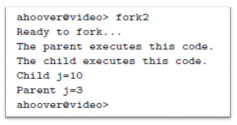
fig 1.14의 프로그램에서 fork() 반환 값을 통해 프로그램은 복제가 실행될 코드에 영향을 줄 수 있다. i 값이 0일 때와 아닐 때 서로 다른 코드 블럭을 실행하게 할 수 있는 것이다. 이에 대한 결과로 fig 1.15같은 정보가 출력된다. 여기서 출력 라인의 순서는 실행마다 달라질 수 있다. fork() 이후에 두 프로세스는 동시에 실행되기 때문에 실행 순서를 예측할 수 없기 때문이다.

그리고 fork() 함수는 반복적으로 호출될 수 있다. 즉, 하나의 프로세스가 여러 개의 새 프로세스를 시작할 수 있으며, 이는 차례로 여러 개의 새 프로세스를 시작할 수 있다. fig 1.16에서는 부모 프로세스는 두 개의 자식 프로세스를 생성하고 부모 프로세스에서 첫번째 fork()로 생성된 자식 프로세스는 두번째 fork를 통해 또 다른 자식 프로세스를 생성한다. 때문에 해당 프로그램에서는 총 4개의 프로세스가 생성되는 것이다.
만약 fork()를 연속 3번 실행하게 된다면 몇개의 프로세스가 생성될까? 2개번의 fork()로 총 4개의 프로세스가 있는데 각각이 또 자식 프로세스를 생성하니깐 8(2^3)개의 프로세스가 생성된다. 그리고 fig 1.16의 출력 순서도 fig 1.15와 같은 이유로 무작위이다.
exec() family
어떤 프로세스가 자식 프로세스를 생성하게 되면 두 프로세스는 같은 프로그램을 실행한다. 이때 자식 프로세스에서 exec() 계열 시스템 콜을 사용한다면 해당 프로세스의 메모리 공간을 새 프로그램으로 교체하게 된다. 이때 pid는 그대로 유지되지만 다른 프로그램을 실행하게 된다. execl(), execlp(), execv(), 등 여러 개의 exec() 함수의 변형이 있다.
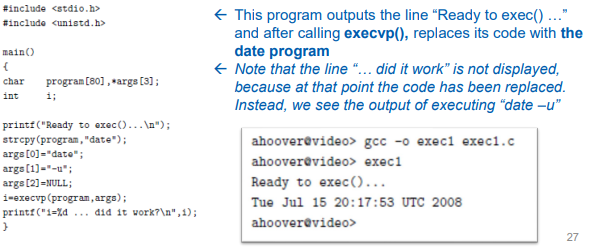
다음 프로그램은 "Ready to exec() ..." 행을 출력하고 execvp()를 호출하여 코드를 date 프로그램으로 바꾼다. "did it work ..." 문자열은 출력되지 않는다. 왜냐하면 그 전에 코드가 교체되었기 때문이다. 대신 "data -u"를 실행한 결과가 표시된다.
wait()
wait()는 자식 프로세스가 끝날 때까지 현재 프로세스를 일시 정지시킨다. 즉 자식이 종료될 때까지 waiting queue로 이동한다. 그리고 해당 함수의 반환 값은 자식 프로세스의 pid이다.
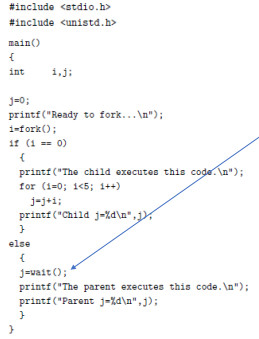
다음 코드에서는 부모 프로세스가 wait()를 실행함으로써 자식 프로세스가 끝날 때까지 대기한다. 때문에 이 프로그램은 무작위가 이닌 정해진 순서로 문자열을 출력한다.
waitpid()를 이용하여 동기화에 대한 세분화된 제어가 가능하다. 이 함수는 특정 pid가 있는 프로세스를 기다리거나 프로세스가 특정 방식/조건으로 종료될 때까지 프로세스를 대기시킬 수 있다.
system()
system() 함수는 fork(), exec(), wait() 함수를 하나의 편리한 호출로 함께 넣는 C 표준 라이브러리 함수이다.
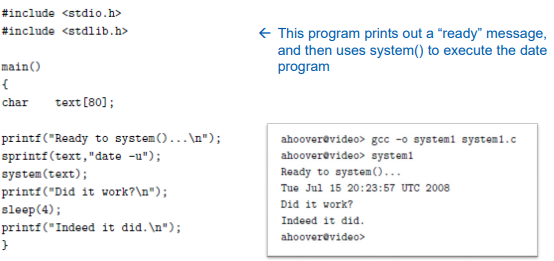
해당 프로그램에서 'system(text)'가 실행되면 해당 함수 내부에서 어떤 일이 일어날까? 우선 부모가 자식을 fork한다. 그리고 자식이 exec하여 date 프로그램으로 자신을 변경한 후 이를 실행한다. 이때 부모는 wait를 실행하여 자식이 종료될 때까지 기다린다. 그리고 자식이 종료되면 부모가 깨어나서 다시 다음 코드를 실행한다.
Process termination
프로세스는 마지막 명령문을 실행할 때 종료되고 OS에 exit()라는 시스템 콜을 사용하여 현재 프로세스를 삭제하도록 요청한다. 그 시점에서 프로세스는 대기 중인 부모 프로세스(wait() 시스템 콜을 통해)에게 상태 값(보통 정수)을 반환할 수 있다. 물리적 및 가상 메모리, 열린 파일, I/O 버퍼를 포함한 프로세스의 모든 리소스는 OS에 의해 할당 해제되고 회수된다.
부모는 abort() 시스템 호출을 사용하여 자식 프로세스의 실행을 종료할 수 있다. 이를 사용하는 몇가지 이유는 다음과 같다.
- 자식이 할당된 리소스를 초과함
- 자식에게 할당된 작업이 더 이상 필요하지 않음
- OS는 부모가 종료되면 자식이 계속 실행되는 것을 허용하지 않는데 이러한 현상을 "cascading termination"이라고 함(즉 모든 자식, 손자 프로세스가 종료됨)
pid = wait(&status);부모 프로세스는 wait()를 이용하여 자식 프로세스의 종료를 기다릴 수 있다고 했다. 이 시스템 콜은 부모가 자식의 종료 상태를 얻을 수 있도록 하는 매개변수를 전달하고 종료된 자식의 pid도 반환한다. 그런데 이러한 wait로 인해 비정상적인 프로세스가 발생할 수 있다.
- 좀비 프로세스: 해당 프로세스는 종료되었지만 부모 프로세스가 아직 wait()를 호출하지 않은 프로세스이다. 자식 프로세스가 생성되고 자식 프로세스가 어떤 값을 부모에게 넘겨준다고 하자. 이때 자식은 종료되었지만 wait()가 호출되지 않으면 프로세스는 죽었지만 넘겨 줄 값은 계속 살아있는 상태인 것이다. 때문에 부모 프로세스에서는 만들어준 자식 프로세스 수만큼 wait()를 호출해야한다.
- 고아 프로세스: wait()를 호출하지 않고 부모가 종료된 프로세스이다. 이를 방지하기 위해 일부 OS에서는 위에서 말했던 cascading termination을 이용한다. UNIX 및 리눅스에서 init 프로세스는 이러한 고아 프로세스를 자신의 자식으로 입양한 뒤에 주기적으로 wait() 호출하여 이들을 종료시킨다.
Single-threaded & Multi-threaded Processes
이번에는 쓰레드에 대해 알아보자. 쓰레드는 프로세스 내에서 자체 실행 상태(CPU 레지스터 및 스택)을 갖는 실행 흐름이다. 생각해보면 우리가 여태껏 이 수업에서 봐았던 프로세스 모델은 프로세스가 단일 스레드로 수행되는 프로그램이었다. 즉 단일 스레드 제어를 통해 프로세스는 한 번에 하나의 작업만을 수행할 수 있었다. 하지만 대부분의 최신 OS는 프로세스가 여러 쓰레드를 실행하여 한 번에 둘 이상의 작업을 수행할 수 있는 기능을 제공한다. 이는 다중 쓰레드가 병렬로 실행될 수 있는 멀티 코어 시스템에서 유용하다.
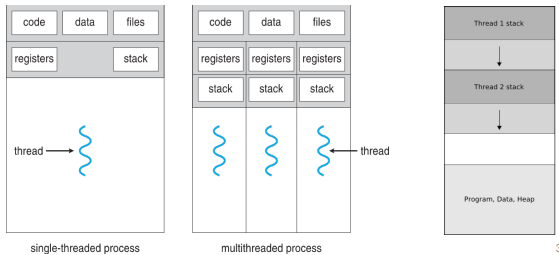
쓰레드는 CPU 활용의 기본 단위이다. 이는 쓰레드 ID, 프로그램 카운터(PC), 레지스터 세트 및 스택으로 구성된다. 그리고 동일한 프로세스에 속한 다른 쓰레드와 코드 섹션, 데이터 섹션 및 열린 파일 맟 신호와 같은 기타 OS 리소스를 공유한다.
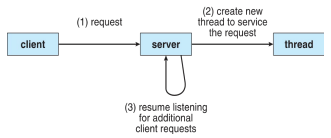
대부분의 최신 소프트웨어 애플리케이션은 다중 스레드를 사용한다. 즉 애플리케이션의 여러 작업을 별도의 스레드로 구현할 수 있다. 예를 들어 다중 쓰레드를 이용한 서버 아키텍처가 있다. 서버가 클라이언트의 요청을 받으면 새 쓰레드를 생성하여 요청에 해당하는 처리를 수행한다. 그리고 기존 서버 쓰레드는 클라이언트의 다른 요청을 받을 준비를 한다.
그리고 대부분의 OS 커널 또한 다중 쓰레드를 사용한다. Linux 시스템에서는 시스템 부팅 시간 동안 여러 커널 쓰레드가 생성된다. 각 쓰레드는 장치 관리, 메모리 관리 또는 인터럽트 처리와 같은 특정 작업을 수행한다. 특수 커널 쓰레드인 'kthreadd'(PID=2)는 다른 모든 커널 쓰레드의 부모 역할을 한다.
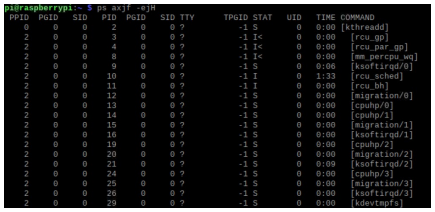
커널 공간에서 쓰레드를 생성해야 할 때마다 kthreadd가 호출된다. 그 이유는 사용자 공간에서의 호출로는 단순한 방법으로 커널 쓰레드를 생성할 수 없기 때문이다. 그리고 이 쓰레드는 'init'(PID=1) 프로세스와는 관련이 없다. 그리고 쓰레드도 PID를 가지는 이유는 리눅스에서는 프로세스와 쓰레드를 동일하게 보기 때문이다. fig 2.3은 라즈베리 파이에서 'ps axjf -ejH'라는 명령을 실행한 결과이다. 많은 쓰레드의 PPID(부모의 PID)가 '2'인 것을 확인할 수 있다.
Benefits of Multithreaded Programming
멀티 쓰레드 프로그래밍의 장점은 다음과 같다.
- 반응성(Responsiveness): 프로세스의 일부가 차단된 경우, 즉 어떤 쓰레드의 실행에 문제가 생겨도 다른 쓰레드에서는 실행을 계속할 수 있다. 이같은 특징은 UI에서 중요하다. 왜냐하면 UI는 계속해서 사용자의 입력을 받을 준비를 를 하고 백그라운드에서 입력에 대한 처리를 진행하기 때문이다.
- 자원 공유(Resource Sharing): 쓰레드는 프로세스의 리소스를 공유하므로 이를 공유하는 것이 공유 메모리 또는 메시지 전달 방법보다 쉽다. 앞의 두방법은 다음에 다룰 IPC에 대한 내용인데 어찌됐든 멀티 쓰레드는 프로세스의 자원을 공유하기 때문에 이를 사용하기 위한 로직을 별도로 구현하지 않아도 된다.
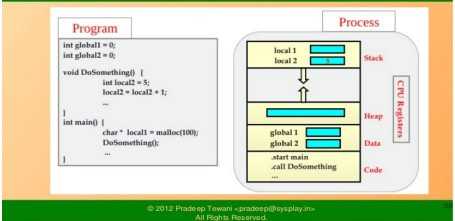
- 경제성(Economy): 프로세스 생성보다 cost가 저렴하고 쓰레드 스위칭은 프로세스간 문맥 교환(context switching)보다 오버헤드가 적다. fig 2.1을 보면 쓰레드를 만드는데는 register, stack 영역만을 필요로 하지만 프로세스를 만드는데는 이외에도 code, data, 등 다른 영역들도 필요로 하는 것을 알 수 있다.
- 확장성(Scalability): 멀티 쓰레드를 이용해야 프로세스는 다중 프로세서 아키텍처를 활용할 수 있다.
Multi-threading Model
쓰레드의 종류에는 user-level 쓰레드 라이브러리에서 관리하는 사용자 쓰레드(user thread)와 kernel-level OS(kthreadd)에서 직접 관리하는 커널 쓰레드(kernel thread)가 있다. 사용자 쓰레드가 실행하다가 OS의 서비스가 필요할 때 시스템 콜을 호출해야 한다. 그럼 커널 쓰레드가 해당 시스템 콜을 받아서 해당하는 로직을 실행해야 한다. 여기서 멀티 쓰레드의 모델은 이 둘의 관계에 따라 다대일 / 일대일 / 다대다로 나눠볼 수 있다.
다대일 관계에서는 여러개의 유저 쓰레드들과 하나의 커널 쓰레드가 매핑된다. 그러므로 한 사용자 쓰레드에서 호출한 시스템 콜을 커널 쓰레드가 처리하는 동안은 다른 사용자 쓰레드의 요청을 처러하지 못한다.
일대일 관계는 사용자 쓰레드에 각각 커널 쓰레드가 매핑된다. 그러므로 유저 쓰레드의 시스템 콜 호출이 block될 일이 없다. 성능은 다대일보다 낫겠지만 유저 쓰레드에서 늘 시스템 콜을 호출하지 않으므로 이 때는 자원이 낭비된다고 볼 수 있다.
다대다 관계는 위 두 방법의 절충안 같은 것인데, 사용자 쓰레드와 커널 쓰레드가 다수 존재하지만 매핑이 되있지 않고 OS가 유동적으로 사용자 쓰레드의 시스템 콜을 처리할 커널 쓰레드를 선택하는 것이다. 어떤 시스템 콜을 처리해야할 때 아무 작업도 수행하고 있지 않은 커널 쓰레드를 선택하여 작업을 시키는 식이다.
Threading Issue: The fork() and exec() System Calls
멀티 쓰레딩 환경에서는 위에서 다뤘던 fork()와 exec()의 의미가 조금 달라질 수 있다. exec()같은 경우에는 모든 쓰레드를 포함하여 실행 중인 프로세스를 교체하기에 일반적으로 동일하게 정상적으로 작동한다. 그런데 fork()와 같은 경우에는 이를 호출했을 때 새 프로세스가 모든 쓰레드를 복제할까? 아니면 복제된 새 프로세스는 단일 쓰레드일까?
이같은 문제 때문에 일부 UNIX 시스템에는 두 가지 버전의 fork()가 있다. 하나는 모든 쓰레드(ex. fork())를 복제하고 다른 하나는 호출한 쓰레드만(ex. fork1()) 복제한다.
Linux Threads
위에서 Linux에서는 쓰레드와 프로세스를 같은 것으로 보기 때문에 둘다 PID로 관리된다고 했다. 이처럼 Linux에서는 쓰레드(또는 프로세스)가 아닌 이둘을 묶은 task라는 용어를 사용한다.

리눅스에서는 쓰레드 생성은 clone()이라는 시스템 콜을 통해 수행된다. 이는 부보 자식 간에 공유되는 리소스를 지정하는 플래그(flags)를 인수로 사용한다는 점을 제외하고는 fork()(생성된 프로세스는 부모와 리소스 공유하지 않음)와 동일하게 작동한다. 따라서 clone()이 호출되면 부모 부모 task와 자식 task간에 공유할 양을 결정하는 플래그 집합이 전달된다 fig 2.4는 이러한 플래그 중 일부이다.
만약 clone()이 호출될 때 플래그가 설정되지 않으면 리소스가 공유되지 않으므로 fork() 호출과 유사한 기능이 나타난다. 즉 fork()는 아무 것도 공유하지 않고 모든 하위 컨텍스트를 복사하는 clone()의 특별한 경우일 뿐이다.
자료 출처
- Abraham Silberschatz, Peter Baer Galvin, and Greg Gagne, “Operating System Concepts (10th Edition) - Wiley 2019
'시스템 프로그래밍' 카테고리의 다른 글
| IPC (Inter-Process Communication) (0) | 2021.12.26 |
|---|---|
| I/O Systems and Operations (0) | 2021.11.29 |
| OS Structures & Linux Overview (0) | 2021.11.12 |
| Operating Systems(OS) Overview (0) | 2021.11.05 |
| Linkers and Loaders (0) | 2021.11.01 |




댓글