계속해서 가상 메모리에 대해 다룬다. 이 글에서는 가상 메모리의 구성 요소 중에서도 page table과 TLBs에 대해 구체적으로 다뤄 보고자 한다. 이전까지는 page table을 간단하게 표현했는데 사실 page table을 효과적으로 구성하는 것은 쉬운 일이 아니다. 때문에 여기서는 page table을 어떻게 관리해야 하는지와 HW적인 도움을 주는 TLBs에 대해 살펴볼 것이다.
추가적으로 이 파트는 캐시에 대한 이해가 필요하다. 컴퓨터 구조 때 다뤘던 내용인데 본인은 잘 기억나지 않아서 따로 찾아봤었다. https://parksb.github.io/article/29.html을 참고했는데 이해하는데 큰 도움이 됐었다.
VM Issue
이전 글 끝에서 다뤄볼 문제들을 언급하고 끝냈는데 다음과 같은 문제들을 생각해봐야 한다고 했다.
- 큰 사이즈의 page table을 어떻게 저장하고 접근할 것인지 (1)
- translation, access control의 과정을 어떻게 더 빠르게 할 것인지 (2)
- 얻어낸 PA를 통해 cahce에 접근하는데 오랜 시간이 소요됨 (3)
VM에서 어떻게 이러한 문제들을 개선하는지 확인해보자.
Issue1: Page Table Size
우선 문제(1)부터 알아보자. 이 문제를 개선하기 위해서는 다음과 같은 경우들을 고려해봐야 한다.
- page table의 사이즈는 얼마나 커야하는가?
- 어디에 page table을 저장해야 하는가?(HW, physical memory, virtual memory)
- 모든 페이지 테이블을 할당하지 않고 어떻게 효과적으로 page table을 저장할 수 있는가?
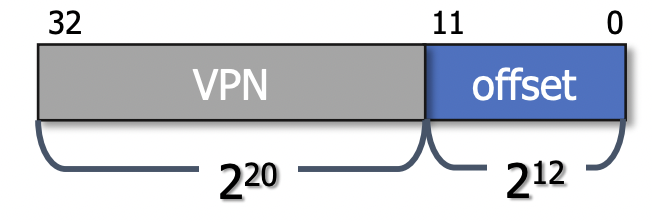
이전까지는 프로세스마다 하나의 큰 page table을 가지고 있었다. 32bit 시스템에서 4KB의 page 크기(계속 이를 기준으로 설명할 예정)를 가지는 경우에는 가상주소는 fig 1처럼 구성되었고 page table의 엔트리 수는 2^32 / 2^12 = 2^20개였다. 그리고 page table의 엔트리는 PFN, valid bit, protection bit, 등의 필드를 가져 총 32bits(4bytes)의 크기를 가진다 이것이 2^20개가 있다고 했으니 page table의 크기는 2^20 * 4bytes = 4MB이다.
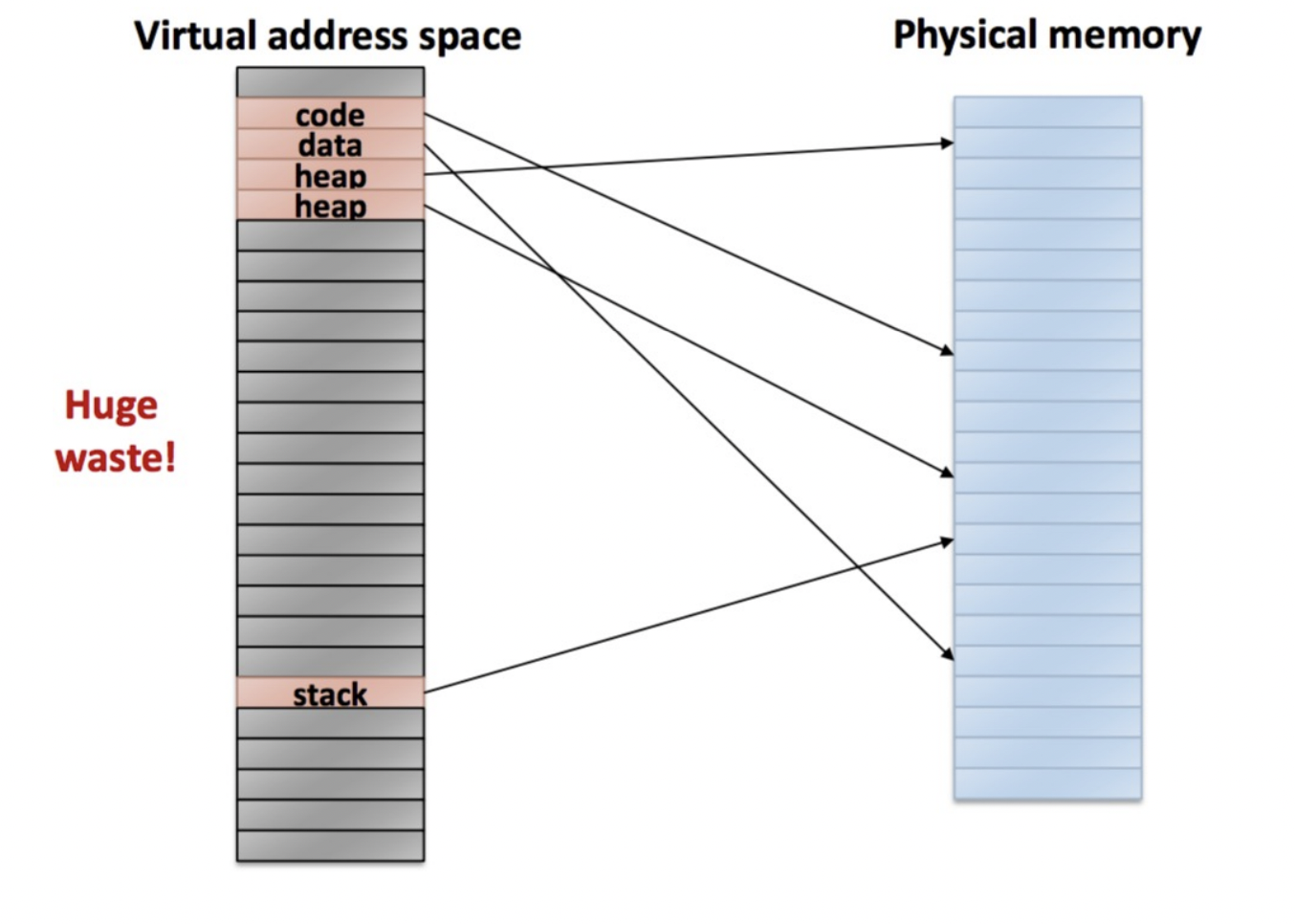
요즘 RAM의 크기가 8/16/32GB인걸 생각하면 그렇게 큰 크기로 안 보일 수 있지만 실제로 상당히 많은 프로세스가 실행되기 때문에 가볍게 볼 수 없는 크기이다. 그리고 만약 page가 하나만 필요한 매우 간단한 프로세스조차도 4MB의 page table을 가지게 된다면 이는 굉장한 공간 낭비가 아닐 수 없다.
Linear Page Table
이러한 공간 낭비의 문제를 인지하고 가장 먼저 드는 생각은 '그렇다면 필요한 페이지 수 만큼의 page table 엔트리만 만들어서 할당하면 되지 않나?'이다. 공간은 효율적으로 사용할 수 있겠으나 이 방법에는 큰 문제가 있다.
우선 프로세스당 4MB 크기의 page table을 가진다고 생각해보자. 즉 가상 주소 공간의 페이지 수만큼 page table이 엔트리를 가지는 것이다. fig 2를 예로 들어보면 100번째 page에 위치한 stack에 접근하기 위해서는 page table의 100번째 엔트리에 바로 접근하여 PFN을 알아내면 된다. 다르게 말하면 base table base register의 값에서 100만큼 더한 주소에 접근을 바로 하면 되는 것이다.
그렇지 않고 필요한 만큼의 크기의 page table을 만들고 이후 더 필요하면 demanding paging을 통해 새롭게 엔트리를 할당하는 방법을 사용한다고 하자. 그렇다면 stack을 찾기 위해 page table의 처음부터 이것이 stack에 해당하는 PFN인지 확인해야 한다. 그러므로 최악의 경우에는 메모리에 한 번 접근하려고 2^20번 엔트리를 확인해야 할 수도 있다. 이 오버헤드가 굉장히 크기 때문에 문제가 되는 것이다.
Solution: Multi-level Page Table
이러한 문제를 합리적을 해결하기 위한 방법은 Multi-level Page Table을 사용하는 것이다. 예를 들어 '부산'이라는 도시를 찾고 싶은데 [서울, 춘천, 대전, 부산, ...]처럼 도시 이름만 들어있는 리스트에서 찾는 것(Linear page table과 유사)이 아니라 [경기도, 경상도, 전라도, 강원도, ...] 리스트에서 경상도를 선택한 다음 경상도 항목이 가리키는 [창원, 거창, 양산, 부산, ...]에서 '부산'을 찾아내는 것이라고 생각하면 될 것 같다.


즉 가상주소를 fig 3와 같이 표현하는 것이다. 20bit로 표현되던 PFN가 Outer page #, Secondary page # 두개로 나누어 진 것을 알 수 있다. 각각 10bits씩 나눠가졌다고 해보자. 이는 2^20개의 엔트리를 2^10개씩 묶은 것이다.
Outer page table은 2^10개의 엔트리를 가지게 된다 여기서 하나를 택하면 그 안에는 Secondary page table 중 하나의 시작 주소가 있고 Secondary page #를 이용하여 가고자 했던 physical memory의 page로 접근할 수 있는 것이다. 이를 그림을 나타내면 fig 4와 같다.
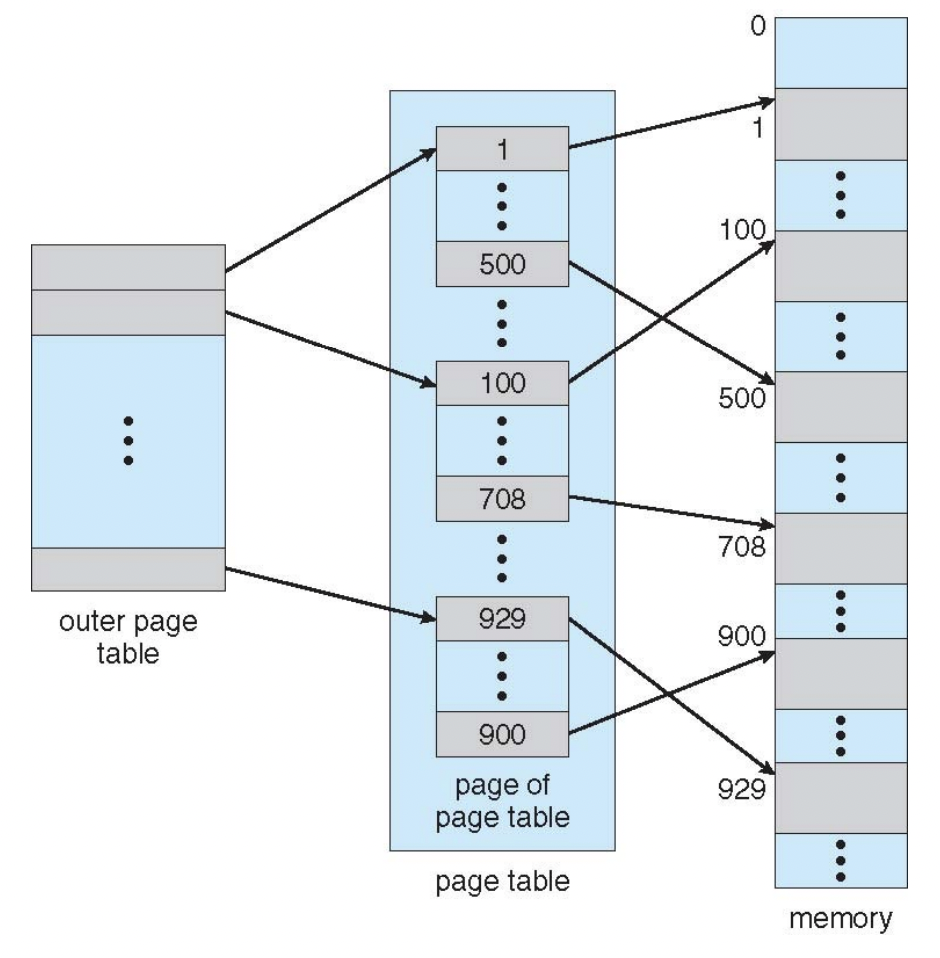
fig 5를 확인해보자. 이와 같은 경우에는 outer page table을 확인해보면 3개의 엔트리(회색)만이 현재 사용 중이다. 그렇기 때문에 2^10크기의 (secondary) page table을 3개만 생성하면 된다. 상위 레벨의 비트에서, 하위 레벨 비트로 갈 수록 주소가 세분화 된다고 생각하면 된다.

fig 6는 multi-level page table을 이용하여 '0xFFA8AFDC'라는 가상 주소와 맵핑된 physical address로 변환하는 과정이다.
- 우선 page table base register을 이용해 outer page table 시작 주소로 접근한다.
- 상위 10bit(3FE)만큼 떨어진 엔트리에 접근하여 데이터를 확인해보니 '0xFFCBE8'라는 page table의 시작 주소를 알아내어 접근한다.
- 이 page table에서 하위 10bit(38A)만큼 떨어진 엔트리에 접근하여 값을 확인하여 PFN을 얻을 수 있게 되었다.
- PFN(0x003A0)과 offset(FDC)을 합쳐 physical address를 알 수 있다.
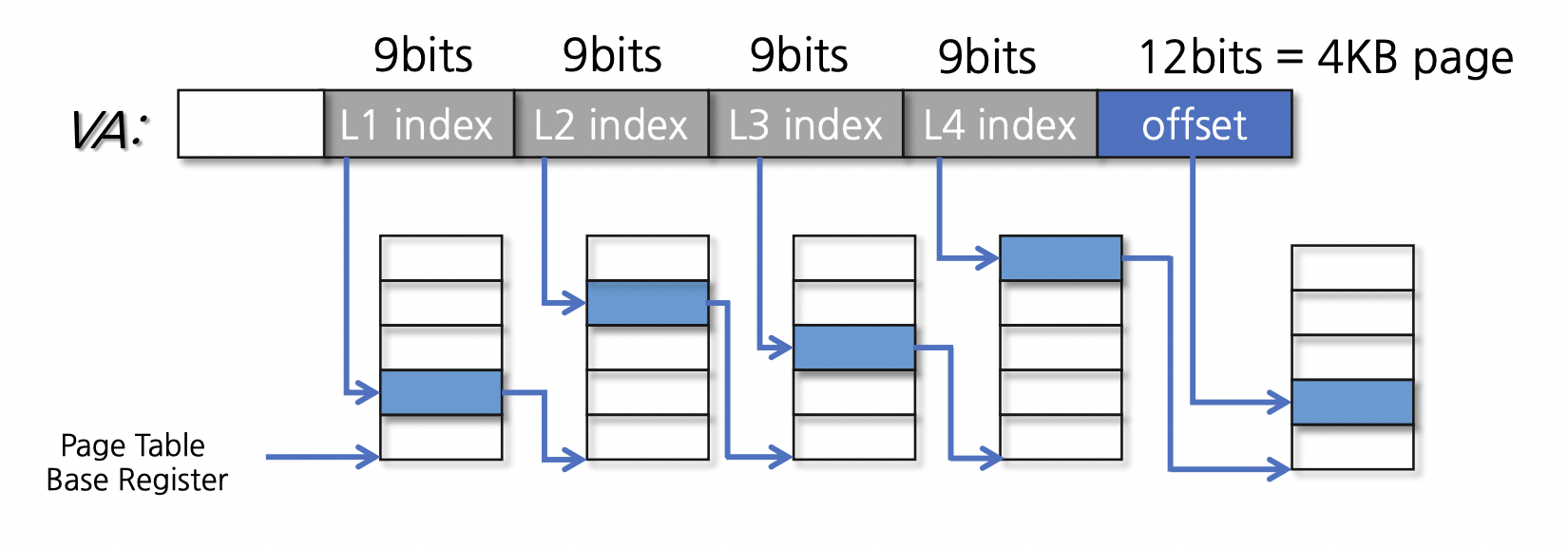
x86 아키텍처의 64bit 시스템에서는 48bit로 주소를 나타내는데(64bit는 너무 큰 듯 함) 4-level의 page table을 사용한다. linear page table의 절충안 같은 느낌이긴 하나 어찌되었든 page table의 level이 늘어날 수록 메모리 접근이 늘어나기 때문에 오버헤드가 많이 발생하기는 한다. 그래서 이를 해결해주기 위해서 HW적인 도움을 받게 된다. 이에 대해서는 다른 종류의 page table을 알아본 뒤에 알아보자.
Hashed Page Table
이 방법은 vitual page number가 hashing이 되어 page table에 들어가게 된다. 이때 page table의 각 element는 VPN과 이에 맵핑되는 PFN, 다음 element의 포인터가 포함된다. 다음 element의 포인터가 있는 이유는 hash가 충돌이 났을 때를 대비하기 위함이다.
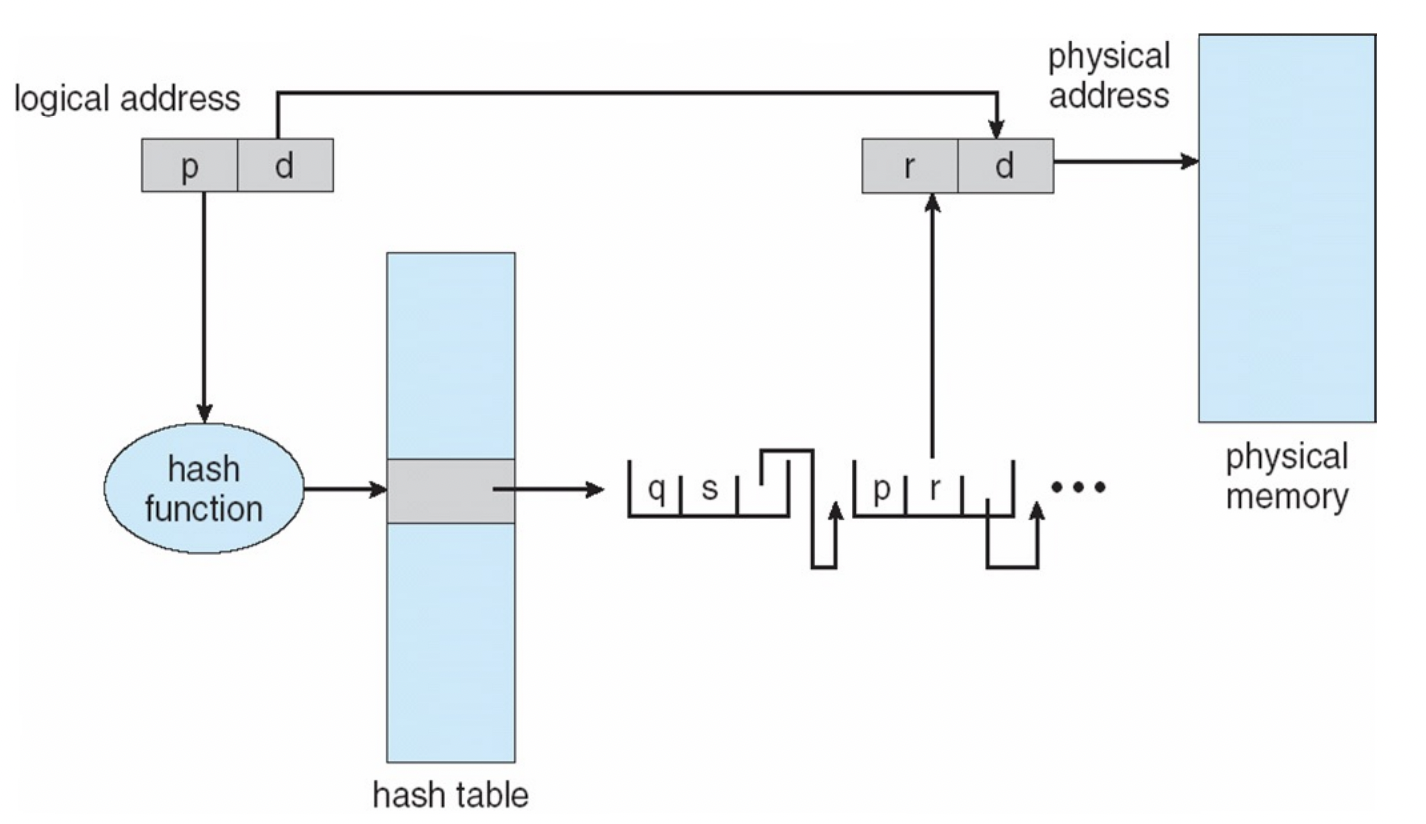
fig 8을 보자. p라는 VPN를 hash 함수에 넣은 후 해당 엔트리로 이동한 다음 해당 버킷에 있는 element들을 포인터를 이용해 확인하면서 p를 찾게되면 해당 element의 r(PFN)을 d와 합침으로써 physical address를 얻을 수 있다.
자주 쓰는 데이터는 캐시(cache)에 넣어서 메모리에 접근하지 않고 바로 처리할 수 있게끔 한다. 이는 paging에서도 적용이 된다. 자주 쓰는 VPN-PFN을 캐시에 담아놓으면 된다. 그렇다면 이러한 cache 성능의 관점에서 봤을 때 multi-level page table과 hashed page table 중 어떤 것이 더 유리할까?
캐시에 저장할 데이터는 지역성(locality)를 가져야 한다. 이러한 지역성은 시간적/공간적 지역성으로 나눠지는데 각각 최근에 참조된 내용은 곧 다시 참조되는 특성(ex. loop), 참조된 주소와 인접한 주소의 내용이 다음에 참조되는 특성(ex. 배열)을 뜻한다. 그렇기 때문에 인접한 page들끼리는 연속하게 위치한 multi-level page table이 공간적 지역성에서 이점을 갖는다.
Inverted Page Table
이 page table은 이름에서도 알 수 있듯이 맵핑 순서를 뒤집었다고 생각하면 된다. 그리고 physical memory frame마다 하나의 page table 엔트리를 할당한다. 이 엔트리에는 VPN과 해당 메모리 공간에 접근하려하는 프로세스에 대한 정보가 담긴다.

fig 9을 보면 이 방법에서 가상 주소는 <pid, page number(p), offset(d)>으로 구성되어 있다. 그러므로 physical memory에 접근할 때에는 page table에서 동일한 pid와 p가 있는 엔트리를 찾고 i번째 항목에서 발견했다면 i와 d를 이용하여 접근해야할 메모리 주소를 확인한다. 다시 말하지만 여기서 page table과 가상 메모리는 1대1 대응이다.
그렇기 때문에 프로세스마다 page table을 가질 필요가 없으므로 효율적인 메모리 관리가 가능하다는 장점이 있으나, 최악의 경우에는 page table 전체를 탐색해야 하므로 성능 저하가 일어날 수 있다는 단점이 있다.
hashed/inverted page table에 대해 알아봤는데 메모리 크기가 점점 증가하면서 이들은 multi-level page table에 비해 범용적으로 적용되기 어렵기 때문에 실제로는 잘 사용되지 않는다고 한다.
Issue2: Memory Acess Frequency
TLB
multi-level page table이 현재는 잘 사용되고 있는데, 이 방법은 메모리 접근이 많아진다는 단점이 있었다. 이 문제를 해결하기 위한 시도 중 TLB(Translation Look-aside Buffer)에 대해 알아보자.

page table을 사용하여 virtual address(VA)를 physical address(PA)로 바꾸는 과정을 주소변환(address transition)이라고 하였다. 그런데 multi-level page table을 사용하면 하나의 메모리 공간에 접근하기 위해 간접적인 메모리 접근이 발생하기 때문에 주소변환 과정이 길어진다. 이를 해결하기 위해 HW적인 도움을 받는다고 조금 전에 언급했었다. 바로 PTEs(Page Table Entry)를 caching하기 위한 HW structure를 두는 것인데 이것을 TLB라고 한다.
CPU에 있는 data/instruction cache 같은 경우에는 메모리에서 자주 접근되는 data를 캐시에 넣어놓기 때문에 입력으로 주소값을 주면 해당 주소에 대한 데이터가 캐시에 있는지 확인하고 data를 출력하는 식이었다. 반면 TLB의 경우에는 VA를 입력으로 받으면 PA를 출력한다. 자주 접근되는 VA에 대한 PA를 미리 가지고 있어서 메모리에 접근하지 않고 바로 PA를 얻어낼 수 있는 것이다.
물론 TLB를 이용하여 접근하고자 하는 VA에 대한 PA를 얻지 못할 수 도 있다. 이를 TLB miss(반대는 hit)라고 하는데 이 경우에는 TLB에서 PA를 얻을 수 없음을 확인하고 메모리에 접근한 뒤 이 정보를 TLB에 담아야 한다. 이때 TLB의 어떤 엔트리를 교체해야 하는지, HW/SW 중에 어느 것이 TLB miss를 handling 할 지 결정해야 한다.
TLB를 다루는 주체에 대해 따져보면, SW가 관리하는 TLB의 경우(ex. Sun, Oracle Sparc, ...)에는 handler를 불러서 page table을 탐색한 뒤 TLB를 채운다. SW적으로 동작하기 때문에 handler가 실행될 때 cost가 발생한다. 반면 비교적 최신 시스템(ex. x86, ...)에서는 HW가 TLB를 관리한다. HW적으로 만들어진 컨트롤러가 PTE를 찾아 TLB를 채우는 역할 을 한다. 이는 OS가 인지하지 못한채 수행된다. 하지만 HW적으로 동작하기 때문에 PTE의 형식이 고정적이어야 한다.
그리고 일반 cache도 L1 cache, L2 cache 처럼 여러 레벨의 캐시로 다뤄지 듯이 메모리의 크기가 점점 증가하면서 TLBs도 L1 TLB(ex. 32 entries), L2 TLB(ex. 512 entries)를 둬서 다루는 엔트리를 늘리기도 한다. 또한 page size를 늘려서 동일한 엔트리 수를 다루지만 더 넓은 영역을 커버하게 할 수도 있다(internal fragmentation을 고려해야 겠지만).
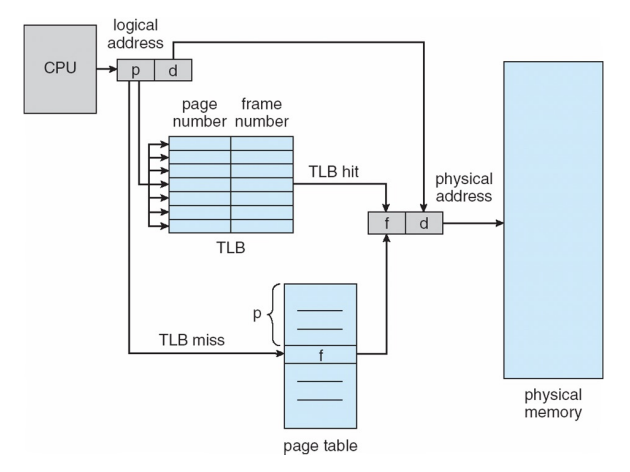
fig 11로 과정을 다시 살펴보자. CPU가 VA를 이용해 PA에 접근하려고 할 때 우선적으로 TLB를 탐색한다. 만약 해당하는 VA가 TLB의 엔트리에 있다면 TLB hit가 되는 것이고 바로 PA를 얻어낼 수 있다. 만약 TLB miss가 되면 page table에 접근(메모리에 접근)하여 PA를 얻어내는 식이다.
그리고 굳이 TLB를 사용하지 않더라도 일반적인 caching에 의해 page table의 엔트리나, physical memory에 있는 일부 데이터는 어쨌든 RAM에 있는 것들이니 cache에 올라와 있을 수도 있다.
Issue3: When to perform address translation
PIPT (Physically-indexed, Physically-tagged)
주소변환(Address Translation)은 프로세서가 instruction이나 data에 접근할 때마다 이것들이 위치한 physical address를 알아야 할 때 수행되었다. 이전까지는 fig 11처럼 (L1)cache에 접근하기 이전에 TLB에 접근하여 VA를 PA로 변환하였다.

그렇기 때문에 이때의 캐시는 PA를 기반으로 동작한다. PA에 해당하는 데이터가 있는지 캐시를 확인하기 때문이다. 이러한 경우를 PIPT라고 한다. 하지만 이 말은 찾고자하는 데이터가 캐시에 있어도 무조건 TLB에 접근해야(만약 TLB에 캐싱되어 있지 않으면 메모리에 있는 page table에 접근해야함) 한다는 것이다. 그렇기 때문에 캐시접근 속도가 느리다.
VIVT (Virtually-Indexed, Virtually-Tagged Cache)

그래서 fig 13처럼 TLB와 캐시의 위치를 바꿔 볼 수 있다. 이러한 방식을 VIVT라고 한다. 즉 VA기반으로 캐시를 탐색하면 굳이 PA로 변환하는 과정 없이도 바로 캐시의 데이터를 가져올 수 있는 것이다. 캐시에 찾고자하는 데이터가 없을 때만 TLB에 접근하면 된다. 그렇기 때문에 캐시에 접근하는 속도가 PIPT보다 빠르다.
하지만 이 방법은 Aliasing problem이 있다. 바로 여러개의 VA들이 같은 PA에 맵핑될 수도 있다는 것(synonyms)이다. 메모리를 공유하는 경우를 생각해보면 될 것이다. 이렇게 되면 같은 캐시의 각 항목의 VA는 다른 값이지만 같은 데이터가 있을 수 있는 것이다. 이때 데이터가 수정되면 같은 physicall address에 대한 값이 담겨있어도 각 항목에는 다른 데이터가 저장될 수 있기 때문에 이러한 consistency를 맞추는 과정은 매우 복잡할 것이다.
예를 들어 cache miss가 발생할 때마다, HW적으로 모든 가능한 위치를 탐색하여 synonyms을 삭제할 수 있는데 이를 확인하기 위해서는 모든 PA들을 확인해봐야 한다. 아니면 context switch가 발생할 때마다 캐시를 비울(flush) 수도 있다. 만약 멀티 프로세서 환경이라면 프로세서가 각각 캐시를 가지기 때문에 해당 문제를 해결하기에는 더 복잡해 진다.
Parallel TLB and Cache Access
위에서 확인해본 각 방식의 문제점을 개선하기 위해 지금은 TLB와 캐시에 병렬적으로 접근하는 방법을 사용한다. 이전까지 PIPT를 사용하자니 캐시 접근 속도가 느려지고 VIVT를 사용하자니 aliasing problem이 발생하였다. 어떤 방법으로 문제를 개선할 수가 있을까?

fig 14를 확인해보자 VA가 PA로 변환되는 과정에서 바뀌지 않는 값이 있다. 바로 page offset이다. 그렇다면 page offset의 일부 비트를 이용하여 cache를 indexing할 수 있다면 TLB에서 PA를 얻으려고 함과 동시에 VA의 page offset을 이용하여 cache내 블록 위치를 알 수 있을 것이다. TLB의 크기가 캐시보다 작으니 우선 indexing을 완료한 뒤 TLB로 physical address를 얻어서 tag matching을 하게 되면 이전 방법보다 더 빠른 속도를 얻을 수 있을 것이다.
fig 14를 기준으로 하면 캐시 set 하나의 크기는 32bytes이니 offset의 하위 5bit는 block offset에 사용된다. 그리고 나머지 7bit를 가지고 indexing에 사용하면 된다. 2^7 = 128이니 128개의 set을 만들 수 있다. 그리고 캐시의 종류에 따른 캐시의 크기를 확인할 수 있다.
단점이라고 한다면 page size에 따라 set의 수가 한정된다는 것이다. page size를 바꾸지 않고 캐시의 크기를 늘리기 위해서는 associativity를 증가시켜야 하는데 결국 cache의 속도가 느려진다. 그럼에도 VM의 일부 bit를 indexing bit에 넣어줘서 캐시의 크기를 늘린다면 어떻게 될까?
Virtually-Indexed, Physically-Tagged Cache

VA의 두개의 bit를 추가적으로 넣어서 indexing을 하게 된다면 fig 15처럼 더 늘어난 캐시 크기를 확인할 수 있다. 하지만 이렇게 되면 하나의 PA에 대해 캐시내 4(2^2)개의 location이 겹칠 수 있다. 즉 aliasing problem이 발생할 수 있다. 그럼에도 이 경우에는 4번만 추가적으로 탐색하면 되기 때문에 약간의 시간을 더 써서 더 큰 캐시 공간을 확보할 수 있다.
- Operating System Concepts, Avi Silberschatz et al.
- Operating Systems: Three Easy Pieces
- Remzi H.Arpaci-Dusseau andAndreaC.Arpaci-Dusseau
- Available(withseveraloptions)athttp://ostep.org
'운영체제' 카테고리의 다른 글
| HDD: Hard Disk Drives (0) | 2022.06.21 |
|---|---|
| Memory Management 4: Page Replacement (0) | 2022.06.15 |
| Memory Management 2 - Paging (0) | 2022.05.19 |
| Memory Management 1 (0) | 2022.05.16 |
| Deadlock (0) | 2022.05.10 |




댓글