저번 글은 시스템 프로그래밍에서도 대부분 다뤘던 내용이라서 중간에 급하게 끝냈었다. 프로세스나 쓰레드는 CPU 자원을 공유하여 프로그램이 동시에 실행되는 것 같은 효과를 얻는다고 했었다. 이 글에서는 어떻게 CPU를 잘 사용하여 전체 시스템에 이로운 방향으로 갈 수 있는지 알아볼 것이다.
CPU Scheduling

프로세스를 전환할 때 두 가지에 대해 생각해야 하는데 하나는 컨텍스트 스위칭 같이 '어떻게' 전환할 것인가(메커니즘)이고 다른 하나는 언제 전환할 것인가(정책)이다. CPU 스케줄링은 실행 가능한 프로세스 집합을 제공하여 다음에 실행할 프로세스를 결정하는 정책이다. 이것에 대해 어떻게 접근할지 살펴보자.
Basic Approaches
Non-preemptive scheduling
여기서 preemptive는 '선점의' 정도의 의미로 이해하면 될 것 같다. 이 기법은 현재 CPU에 올라와 실행 중인 프로세스가 스스로 CPU를 내려놓는 것이다. 쉽게 말해보자면 현재 실행 중인 프로세스가 '아, 이제는 할 게 없으니깐 다른 프로세스에게 CPU를 양보해야지.'하면서 자원을 넘겨주는 것이다. 그렇기 때문에 이러한 기법을 사용할 때는 프로그램 작성 시 CPU를 내려놓는 경우를 생각하여 프로그램을 작성해야 한다. 다르게 생각해보면 어떤 프로그램이 CPU를 내려놓지 않게끔 한다면 CPU를 독점할 수 도 있다. 그렇기 때문에 해당 방법은 잘 사용되지는 않는다.
Preemptive scheduling
그렇기 때문에 대부분의 OS에서는 Preemptive scheduling을 사용한다. 이 기법은 스케줄러가 프로세스들의 컨텍스트 스위칭을 강제할 수 있다. 그렇기 때문에 시스템에서 CPU 자원을 잘 사용할 수 있게끔 할 수 있다. 하지만 그러기 위해서는 몇가지 경우에 대해 어떻게 처리해야 할지 생각해봐야 한다. 예를 들어 다음과 같은 경우가 있을 것이다.
- 어떤 프로세스가 shared data를 업데이트하고 있는 와중에 preempt 되었을 때
- 시스템 콜 내부의 프로세스가 preempt 되었을 때
Terminologies
몇가지 용어에 대해 정리하고 넘어가보자.
- Workload: 도착 시간, 실행 시간 등 작업(프로세스)에 대한 서술이다.
- Schedular: 언제 작업을 실행시킬지 결정하는 로직이다.
Scheduling Criteria
Metric은 현재 스케줄링이 잘되고 있는지에 대한 측정치이다. 하나로 정할 수 있는게 아니고 turnaround time, response time등이 있다. 그리고 이러한 정보들이 스케줄링의 기준이 된다.
- CPU utilization: CPU 활용도를 높여야 한다. 즉 최대한 CPU를 가만히 냅두지 않고 계속 작업을 시켜줘야 한다.
- Throughput: 시간 당 얼마나 많은 프로세스들이 실행되는지
- Turnaround time: 한 프로세스의 실행 시간
- Waiting time: 한 프로세스가 ready queue에서 대기하는 시간
- Response time: 요청이 보내진 뒤 해당 요청에 대한 첫 응답이 생성되기까지의 시간. 예를 들어 웹서버에게 요청을 보내고 응답을 받기까지의 시간, 키보드를 입력하여 그 내용이 화면에 보이기까지의 시간 등이 있다.
Workload Assumptions
이제 몇가지 스케줄러를 살펴볼건데 실제 환경에서는 이뤄지기 힘든 사항들이나 원활한 이해를 위해 몇가지 가정을 한 뒤 하나씩 무시하면서 실제상황에 가깝게 접근해보자.
- 각각의 작업은 동일한 시간이 소요된다.
- 모든 작업은 동시에 도착하였다.
- 한번 작업이 시작되면, 끝날 때까지 동작한다.
- 모든 작업은 I/O없이 CPU만 사용한다.
- 모든 작업의 실행 시간을 알고 있다.
그리고 여기서 metric으로는 일단 turnaround time에 초점을 맞출 것이다.
$$T_{turnaround}=T_{complete}-T_{arrival}$$
FIFO or FCFS (First In(Come), First Out(Served))
FIFO는 말 그대로 먼저 온 것부터 먼저 처리하겠다는 뜻이다. 드라이브 스루를 생각해보자. 그렇다는건 먼저 도착한 프로세스가 다 실행될 때까지 끝까지 기다려야 한다는 것이다. 즉 위에서 언급했던 Non-preemptive라고 볼 수 있다. 작업들이 동등하게 다뤄지기 때문에 어떤 작업이 먼저 실행되거나 다른 작업의 실행을 막을 수 없다. 이를 여기서는 starvation이 없다라고 한다. 즉 다른 프로세스가 새치기를 할 수 없다는 것이다.
FIFO는 어떻게 보면 합리적으로 보일 수도 있지만 당연히 문제점을 가진다. 한 작업만을 처리하기 때문에 뒤의 작업들이 계속해서 쌓이는 Convoy Effect가 발생할 수 있다. 이로인해 만약 간단한 작업보다 복잡하고 큰 작업이 앞에 위치한다면 평균 trunaroundtime이 증가한다. 생각을 해보자 100초가 걸리는 작업때문에 1초면 끝나는 작업이 실행되지 못하는 경우가 생길 수 있을 것이다.
Example


fig 2-1 처럼 3개의 프로세스가 있는데, \(P_1,P_2, P_3\) 순서대로 도착한다고 가정해보자. 그럼 fig 2-2처럼 작업이 처리될 것이다. 이때 각각의 대기 시간(Waiting time)을 알아보면 다음과 같다. $$P_1=0, P_2=24, P_3=27$$
이를 통해 평균 대기 시간을 구해보면 \((0+24+27)/3=17\)이다.
그럼 \(P_2, P_3, P_1\)순서로 도착하면 각 대기 시간과 평균 대기시간은 어떻게 될까? 계산해보면 다음과 같다.
$$Waiting time: P_1=6, P_2=0, P_3=0$$ $$Average Waiting Time: (6+0+3)/3 = 3$$
이처럼 같은 작업들이라도 어떤 순서로 도착하느냐에 따라 평균 대기시간이 크게 차이가 나는 것을 확인해볼 수 있다. 만약 긴 작업이 짧은 작업들보다 먼저 도착할 때, I/O 작업도 추가된다고 생각해보자. 어찌됐든 긴 작업이 끝나기 전까지 CPU나 I/O 중 하나는 idle한 상태가 되어 가만히 놀게 놔두게 된다.
Shortest Job First(SJF)
SJF는 위의 FCFS를 개선한 것이다. 각 작업들이 서로 다른 실행시간을 가질 때(가정1 무시), 작업들 중에서 가장 짧은 작업을 우선적으로 선택하여 처리하는 것이다. 그렇기 때문에 최적의 turnaround time을 가질 수 있다. 이 역시도 non-preemptive이다.
하지만 이 방식에도 문제점은 존재한다. 실제 상황에선 기존의 작업들 이외의 다른 작업들이 언제 도착할지 알 수 없으므로 이를 고려할 수 없다. 다르게 말하면 작업들 중 뒤에 처리해야할 긴 작업이 있는데 계속해서 짧은 작업들이 도착한다면 긴 작업은 계속해서 처리되지 못한다는 것이다. 즉 이 방법에서는 starvation이 발생할 수 있다.
Example


fig 3-처럼 프로세스들이 있을 때 SJF에서는 \(P_4, P_1, P_3, P_2\)순서로 작업을 처리한다. 이때의 평균 대기 시간은 \((3+16+9+0)/4 = 7\)이다. 하지만 \(P_2\)가 먼저 처리 중인 상황에서 나머지 프로세스들이 도착했다면, 위와 같은 결과는 나오지 못한다. 이것이 SJF의 문제점이다.
Shortest-next-CPU-burst
위와 같은 문제점을 해결해보기 위해 이제 가정2, 가정 3를 지워 작업이 동시에 도착하지 않고 preemptive가 가능하다고 해보자. Shortes-next-CPU-burst는 SJF의 preemptive 버전이다. STCF(Shortest Time to Completion First)라고도 한다.

fig 4를 보면, 시간 100이 소요되는 작업이 수행 중, 20초 뒤에 10이 소요되는 작업 B, C가 도착했을 때 각각 남은 소요시간은 80, 10, 10이다. 이때 작업을 전환하여 B, C를 먼저 처리해준 뒤에 다시 A를 처리한다.
Example

예시를 보자. 이번 예시에는 arrival time이 추가되었다. 각 프로세스가 도착할 때마다 프로세스 중 가장 짧은 시간이 소요되는 작업을 선택하여 실행한다.
Round Robin (RR)
Round Robin은 우리가 이전까지 배웠던 프로세스 간 전환 방법과 매우 유사하다. 여기서는 각각의 작업이 time slice(or time quantum)이라는 단위로 잘게 쪼개진다. time quantum은 tick이라는 최소 단위로 이루어져 있다. time quantum을 너무 짧게 잡아놓으면 반응성은 좋을 수 있으나 당연히 자주 컨텍스트 스위칭이 발생하므로 이에 대한 오버헤드가 증가한다. 반대로 너무 길게 잡아놓으면 컨텍스트 스위칭 오버헤드는 적겠지만 반응성이 감소하게 된다. 어쨌든 이 방법에서는 각 프로세스의 time quantum을 번갈아 가면서 처리하게 된다. 그러므로 preemptive하고 non-stravation하다.
프로세스들을 번갈아가면서 실행하기 때문에 보통 SJF보다 더 긴 turnaround time을 가지지만 responsive time에서는 이득을 볼 수 있다. 그렇기 때문에 RR에서는 SJF와 달리 response time에 초점을 맞춘다.
$$T_{response}=T_{firstrun}-T_{arrival}$$
Example (time quantum = 4)

fig 4-3에서 시간 4와 7에서는 다른 프로세스를 동작해야 하므로 컨텍스트 스위칭이 발생한다. 그 이후에는 동일한 프로세스를 실행하기 때문에 time quantum마다 컨텍스트 스위칭이 일어나지는 않는다. 그리고 당연하지만 time quantum의 시간은 컨텍스트 스위칭보다는 길어야 한다.
Priority Scheduling
이전까지 방법에서는 각 프로세스들의 중요도에는 차이가 없이 동일하게 다뤄졌다. 하지만 어떤 프로세스는 긴급하게 처리되어야할 필요가 있다. 때문에 이 방법에서는 각 프로세스가 다른 priority를 가질 수 있다. 그렇기에 나중에 도착한 작업이라도 priority가 높다면 우선적으로 처리될 수가 있다. 그렇기 때문에 이 방법은 preemptive와 non-preemptive의 성격을 동시에 가진다. 같은 우선 순위를 가지는 프로세스들끼리는 non-premmptive이지만, 다른 우선 순위를 가지는 프로세스들이 있을 때는 high-priority한 작업이 끝나기 전에는 low-priority한 작업은 수행될 수 없기때문에 starvation문제(preemptive에서 잘 발생하던 문제였음)가 발생할 수 있기 때문이다.
Multi-Level Feedback Queue (MLFQ)
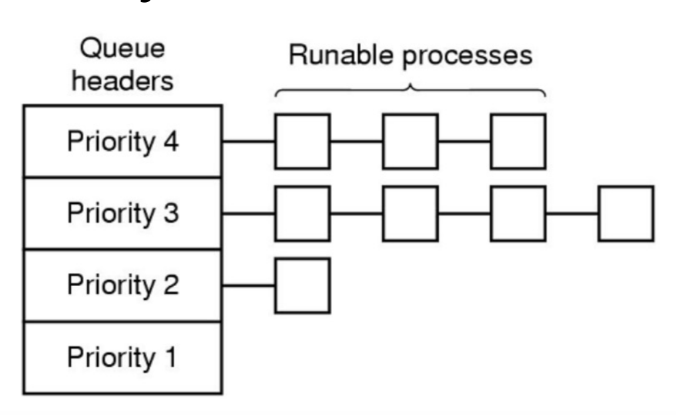
MLFQ에서는 실행가능한 프로세스들의 priority에 따라 해당하는 큐에 위치시킨다. RR에서는 같은 큐, 즉 우선순위가 높은 큐에서 프로세스가 전환되어 실행된다. 정리하면 다음과 같은 규칙을 세울 수 있다.
Rule 1: 만약 priority(A) > priority(B), A 실행(B는 실행X)
Rule 2: 만약 priority(A) = priorty(B), A&B는 RR에서 실행
Incorporating I/O
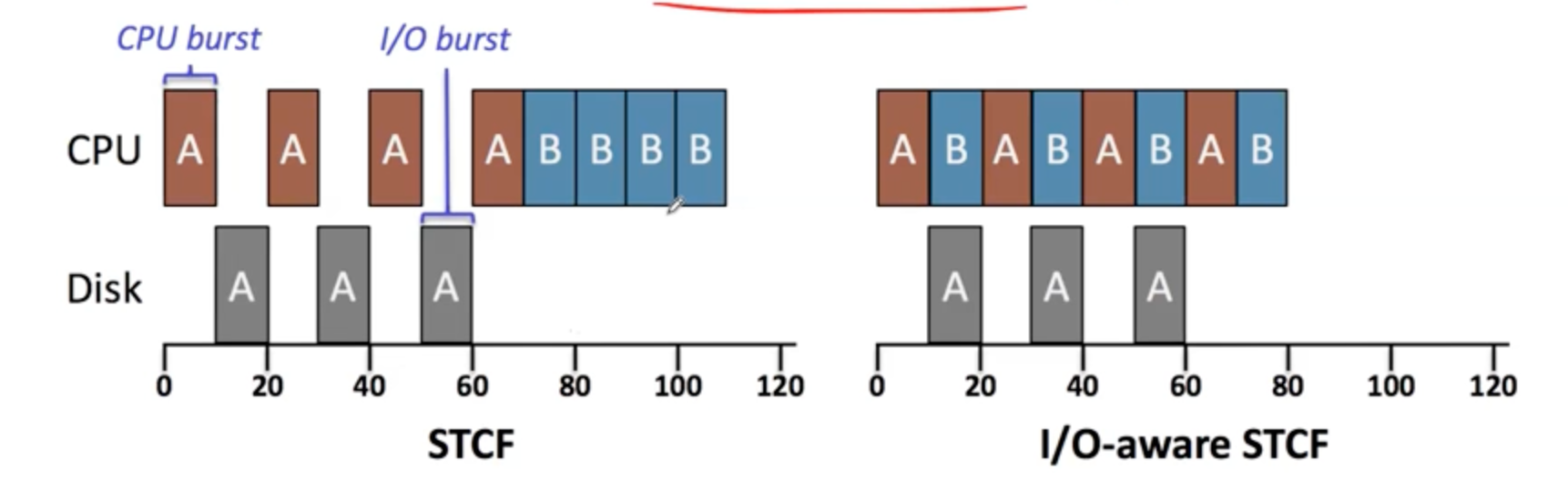
이제는 프로세스는 CPU만 사용한다는 가정 4도 없애보자. 원래 프로세스는 CPU도 사용하지만 I/O 작업을 수행하기도 하니깐 말이다. I/O를 하는 동안은 CPU를 사용하지 않기 때문에 최대한 CPU와 I/O를 오버랩하는게 중요하다. STCF에서 I/O를 고려한다면 fig 6-1과 같은 차이를 보인다. 이전 글에서 프로세스의 상태를 떠올려보면 A가 수행하다가(running) I/O작업이 필요할 때 waiting 상태로 전환되고 이때 B를 실행시킴으로써 CPU 작업과 I/O를 동시에 할 수 있게 된다.
Towards a General CPU Scheduler
이제까지의 내용을 되짚어보면 일반적으로 좋은 스케줄러가 되려면, 상충관계가 있긴하지만 turnaround time과 response time을 최대한 줄여야 한다. 그리고 앞서 세웠던 가정들을 하나씩 제거하면서 발생하는 문제점을 파악하였는데, 마지막으로 가정 5를 지우면 '프로세스의 실행 시간을 알 수 없다'라는 문제가 추가로 발생하게 된다. 그렇다면 어떻게 스케줄러는 각 작업의 특징을 파악하고 더 나은 스케줄링을 구현할 수 있을까? 기술적이지 않고 두루뭉실한 이야기지만 과거의 경험을 이용하여 미래를 예측해보는 것이다. 예를 들어 자주 쓰이는 프로세스를 파악해 해당 프로세스에 대한 정보는 캐시에 담아둬서 컨텍스트 스위칭의 속도를 높이는 방법 등이 있을 것이다.
- Operating System Concepts, Avi Silberschatz et al.
- Operating Systems: Three Easy Pieces
- Remzi H.Arpaci-Dusseau andAndreaC.Arpaci-Dusseau
- Available(withseveraloptions)athttp://ostep.org
'Computer Science > 운영체제' 카테고리의 다른 글
| Synchronization 2 (0) | 2022.04.21 |
|---|---|
| Synchronization 1 (0) | 2022.04.19 |
| Scheduling 2 (0) | 2022.04.12 |
| Processes & Threads (0) | 2022.03.24 |
| Architectural Support for OS (0) | 2022.03.17 |




댓글