멀티프로그래밍, 멀티쓰레드 환경에서는 다양한 문제가 발생할 수 있다. 예를 들어 프로세스들이 공유 메모리에 접근하려고 하기 때문에 실행 때마다 다른 결과가 나오는 race condition이 발생할 수 있다. 이같은 문제를 해결하기 위한 방법을 synchronization이라고 한다. synchronization이 필요한 이유를 예시로도 한번 살펴보자.
Ex 1. Bank Account

fig 1-1을 보자. 계좌(acct_t)들이 있고 이 계좌는 각각 잔액(balance)정보가 있다. 또 인출(trans_t)정보들이 있고 그 안에는 id(user account)나 amount(얼마를 인출할건지)등의 정보들이 있다. 그리고 이 잔액을 인출하는 debit 함수가 있다. 이를 보면 이 예제는 계좌의 잔액을 다른 계좌로 이체하거나 인출하는 등의 예제라고 할 수 있겠다. for문을 보면 인출 정보를 보고 id로 지정된 계좌에서 amount만큼의 돈을 인출한다.
어쨌든 해당 작업을 처리하기 위해서는 debit()을 실행해야 하는데 이를 싱글코어, 싱글 프로세스에서 실행하는게 아니라 멀티코어, 멀티프로세스, 멀티쓰레드 환경에서 실행된다고 하면 어떤 문제가 발생할 수 있을까?

조금 더 자세히 들어가보자. fig 1-2의 debit()함수는 해당 id의 잔액(accts[id].bal)이 인출하려는 금액(amt)보다 많을 때에만 금액을 인출할 수 있게끔한다. 이 함수를 여러개의 쓰레드가 입력을 받아서 병렬젹(parallel)으로 동작시킬 수 있다. 여기서 계좌들은 global하므로 이 값들이 따로 레지스터에 저장되지 않는 반면 id와 amt는 private하기 때문에 r1, r2같은 레지스터에 저장된다(이 과목의 선수과목에 컴퓨터 구조도 있다). 그렇기 때문에 if문은 fig 1-2의 오른쪽에 있는 어셈블리 코드처럼 변환될 수 있다.
- 0: 행에서는 accts의 주소에 id만큼 더한 값을 r3에 넣어주고 있다. 이것은 accts[id]가 위치한 주소를 r3에 넣어준 것이다.
- 1: 행에서는 r3에 위치한 값을 읽어서 r4로 가져온다.
- 2: 행에서는 r4(accts[id]의 값)과 r2(amt 값)을 비교하여 r4가 r2보다 작다면 끝내고 그렇지 않다면 다음 행을 계속 실행한다.
- 3: 행은 r4의 값이 r2의 값 이상일 때 실행된다. r4-r2의 값을 다시 r4에 넣어준다.
- 4: 행에서는 r4에 저장된 값을 accts[id]의 주소(r3에 저장되어 있음)에 넣어준다. 레지스터에 있는 값을 메모리에 넣어준 것이다.
이렇게 어셈블리로 코드를 뜯어본 것은 CPU는 instruction 하나하나를 실행하면서 동작하기 때문이다. 이제 sychronization이 발생하는 상황을 알아보자. 두번의 $100 인출이 #241 계좌에서 발생한다고 하자. 각각의 인출은 서로 다른 프로세서(ATM기)에서 수행된다.

처음의 500은 #241 계좌의 잔액이다. Thread 0에서 0:~4:까지 실행하는데 :4가 실행이 끝나야 메모리에는 비로소 500이 아닌 400이라는 값이 저장된다. 이것이 끝난 뒤에 Thread 1에서 $100을 인출하려고 하여 0:~4:까지 수행하면 이제 메모리에는 400이 저장되는 것이다. 이러한 과정에서는 특별한 문제가 없어 보인다.

문제가 되는 상황은 fig 2-2와 같은 상황이다. Thread 0에서 0:~3:까지 수행하고 컨텍스트 스위칭이 발생하여 4:를 수행하지 못한채 Thread 1이 수행되면 어떻게 될까? Thread 0이 메모리에 400을 쓰려고 하는 순간 Thread 1이 400을 써버린 것이다. Thread 1이 끝난 뒤 Thread 0이 :4를 수행하여도 메모리에 쓰여지는건 레지스터에 있던 400이라는 값이기 때문에 문제가 발생하게 된다. 잔액이 $300이어야 하는데 여전히 $400이니 말이다.
이처럼 여러개의 쓰레드가 공유하는 데이터에 동시에 접근할 때 순서를 결정하거나 한 쓰레드가 update하는 동안 다른 쓰레드는 대기하는 등의 방법을 알아야하기 때문에 우리는 synchronization에 대해 이해할 필요가 있는 것이다.
Synchronization Problem
정리해보자. 앞의 예제는 쓰레드 2개가 concurrent하게 돌아갔었다. 그리고 이 경우에는 어떤 경우에는 제대로 작동할 수도, 어떤 경우에는 의도와 다른게 작동할 수 있었으므로 non-deterministic한 결과를 만들어 낸다. 때문에 디버깅이 매우 어렵다. 이처럼 두 개 이상의 쓰레드가 동시에 공유 자원에 접근했을 때 발생하는 상황을 race condition이라고 한다.
이러한 문제를 막기 위해서 공유 자원에 접근할 때는 synchronizaiton 메커니즘이 필요하다. synchronization의 단점이나 어려움에 대해 간단히 말하자면 synchronizatioin은 어떻게 보면 동시성을 저해하여 성능을 저하시킬 수도 있다. 그리고 스케줄링은 user application이 의식하지 못한 채 동작하여 프로그래머가 제어할 수 있는 사항이 아니기 때문에 더 어려운 문제이다.
이제 synchonization이 필요한 상황이나 이유는 알았으니 이제 방법에 대해서 알아보도록 하자.
Critical Section

일단 critical section(cs로 줄임)에 대해 이해할 필요가 있다. cs은 공유 자원에 접근하는 코드들을 말한다. 좀 전의 account 예시에서는 if문이 이에 해당한다. 당연히 문제가 발생하지 않으려면 cs에서는 하나의 쓰레드만 동작해야 한다. 예를 들어 fig 1-2의 0:~4:를 동작시키는 중에는 다른 쓰레드가 실행되서는 안되는 것이다. 즉 cs는 atomically하게 동작(더 쪼개지지 않음)해야 한다는 뜻이다.
그렇게 하기 위한 가장 간단한 방법은 cs의 앞 뒤에 자물쇠(lock)를 두는 것이다. cs 실행 전에는 쓰레드들이 열쇠를 들고 들어갈 수 있지만 어떤 쓰레드가 자물쇠를 들고 cs에 들어가서 입구를 잠그게 되면 cs를 끝내고 열쇠를 반납하기 전까지는 다른 쓰레드가 cs를 실행할 수 없게되는 것이다. 이것은 mutual exclusion(상호 배제)가 이루어 졌다고 할 수 있다.
Locks
방금전에 lock에 대해 개념적으로 이해했다. 그럼 이 lock을 어떻게 만들어야하는지 알아보자. lock은 두가지 operation을 통해 상호배제를 제공하는 객체라고 할 수 있겠다. 예를 들어 acquire()는 lock이 free가 될 때까지 기다리는 것이고, release()는 lock을 해제하고 acquire()에서 대기하고 있는 쓰레드를 깨우게 한다고 할 수 있다.
acquire()에 들어가 있는 쓰레드가 lock이 풀렸는지 확인하는 방법은 두가지가 있다. 하나는 acquire 내의 쓰레드가 계속해서 lock이 풀렸는지 확인하는 spin(spinlock) 방법이 있고, 다른 하나는 cs를 실행하고 있는 쓰레드가 lock을 푼 것을 알려줄 때까지 기다리면서 cpu는 다른 작업을 하고 있는 block&wait(mutex, semaphore) 방법이 있다.
Requirements for Locks
Lock을 통해 이뤄내야 하는 것들에 대해 정리하고 넘어가자.
- Correctness: lock을 쓰는 이유는 당연히 정확한 결과를 얻어내기 위해서이다. 이를 위해서는 다음을 할 수 있어야 한다.
- Mutual exclusion: 오직 한번에 하나의 쓰레드가 cs에 들어갈 수 있다.
- Progress(deadlock-free): 만약 몇몇 쓰레드가 cs에 들어가길 원한다면 그 중 하나만 들어가게 해야한다.
- Bounding wating(starvation-free): 각각의 모든 쓰레드가 결국에는 cs에 들어갈 수 있어야한다.
- Fairness: 각각의 쓰레드는 lock을 받을 공정한 기회를 얻어야한다.
- Performance: 어쨌든 lock은 correctness를 위해 추가하였기 때문에 이 자체는 오버헤드이다. 이를 최대한 적게 하는 것이 성능에 유리하다.
An Initial Attempt (Spin Lock)

lock을 fig 4와 같이 구현해 볼 수 있을 것이다. lock이라는 변수가 있고 acquire()에서는 이 변수가 1이라면 이것이 0이 될 때까지 기다린다. lock이라는 값이 0이면 lock에 1을 써준다. 반면에 require()에서는 lock의 값을 0으로 만들어준다.
acquire()에서 A0:, A1:을 통해 lock에 있는 값을 r6에 넣어준 뒤에 이 값이 0과 같지 않은지 판단하여 같지 않다면 다시 A0로 돌아가고 같다면 A2를 수행하여 r6에 1을 넣고 A3에서 이 값을 lock의 주소의 데이터로 넣어준다. 어쨌든 잠겨있다면 A0, A1을 계속 반복하기 때문에 spin lock이라고 불린다.
release()는 lock 주소의 데이터를 0으로 바꿔주는 단순한 기능이다. 이 것들을 가지고 다음 예시를 보자.

fig 5-1을 보자 Thread 0이 3:까지만 실행하고 스위칭이 발생하여 Thread 1이 실행되어도 Thread 0이 cs 진입전에 acquire(lock)을 해줬기 때문에 계속해서 spin만 하다가 자신의 cpu 시간을 다 소모한다. 그리고 다시 Thread 0이 실행되어 4:를 실행하여 결과적으로는Tread 0만 명령을 수행한 것이다. 그렇다면 이제 적어도 상호배제는 제대로 이루어진 것일까?

fig 5-2는 acquire()도 명령 단위로 나타낸 것이다. acquire()도 여러개의 명령으로 이루어져 있기 때문에 만약 acquire() 수행 도중에 스위칭이 발생하게 되면 Thread 0도 lock 0이라서 안 잠겼있는 걸로 인지하고 Thread 1도 lock이 아직 1로 바뀌기 전에 읽었기 때문에 안 잠겨있는 걸로 인지하게 된다. 그렇기 때문에 두 쓰레드 모두 cs에 들어갈 수 있게 되는 것이다. 이러한 문제는 어떻게 해결할 수 있을까?
Peterson's Solution: Algorithm for Process \(P_i\)
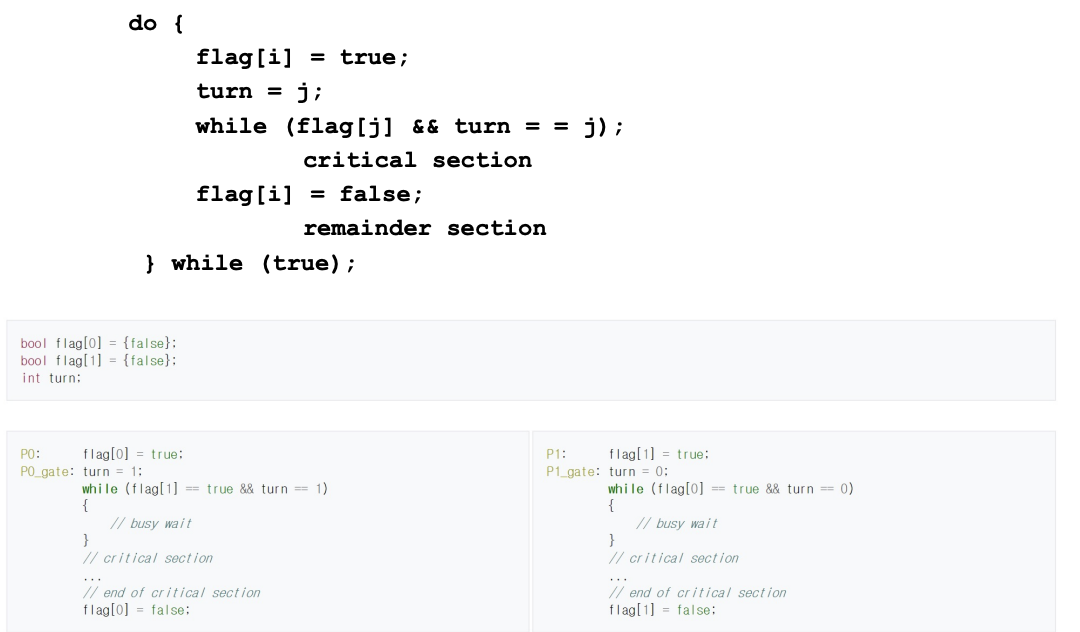
fig 6의 코드를 살펴보자. flag를 통해 자신이 지금 cs에 들어가려고 시도하는지 확인하고 turn을 통해 자신말고 다음에 누가 cs에 들어가야하는지 확인한다. P0 입장에서는 flag[1]==true, turn==1이라면 P1이 끝날 때까지 기다릴 수 있고 P1 입장에서는 flag[0]==ture, turn==0이면 P0이 끝날 때까지 기다리는 것이다. 이러한 알고리즘은 쓰레드가 2개일 때는 유효하지만 그 이상 쓰레드가 늘어나면 좋은 방법이 아니다.
Architectural Support for Synchronization
위 처럼 SW적으로 문제를 해결하려고 하면 완전히 문제를 해결할 수 없기 때문에 우리가 쓰는 시스템에서는 컴퓨터 아키텍처의 도움을 받아서 synchronization을 만들고 있다.
Test and Set

ISA에서는 test and set이라는 atomic한 instruction(read-modify-write를 한번에 수행하는 명령)을 제공한다. test and set은 동시에 새로운 값으로 업데이트 하려고 하면 이전 값을 반환하고 그렇지 않으면 새 값을 써준다.
Compare and Swap

이것은 x86, Sparc 등의 아키텍처에서 볼 수 있는 test and set의 일종이다. 위의 c언어로 이뤄진 코드를 보면 알겠지만 실제 값(*value)이 내가 예상했던 값(expected)과 같을 때만 새 값(new_value)으로 바꿔주고 아니면 이전 값을 되돌려주는 코드이다. 예를 들어 lock variable 값을 읽은 뒤에 내가 기대했던 값도 0이고 실제 값도 0이었다면 value 값을 1로 바꿔주고 기대했던 값이 0인데 실제 값이 1이었다면 lock을 하지 못하는 것이다. 이것을 cas같은 한번의 insturction으로 가능하게 하는 것이다.

이처럼 원래는 몇 개의 instruction으로 이뤄진 작업을 하나의 instruction으로 할 수 있으므로 fig 5-2와 같은 문제가 발생하지 않는다.
Problem of spinlock
spinlock에 대해 알아봤다. 하지만 이 방법은 프로세스가 대기하고 있는 동안 다른 프로세스를 실행할 수 없다. 이는 cpu 사이클 낭비를 초래하게 되는 단점이 있다. 그러니 critical section(cs)의 길이가 짧을 때는 몰라도 길어진다면 비효율적인 성능을 가지게 된다. 또한 결국에는 모든 프로세스가 cs에 들어갈 수 있어야 한다는 bounded wating 또한 충족할 수 없다.
- Operating System Concepts, Avi Silberschatz et al.
- Operating Systems: Three Easy Pieces
- Remzi H.Arpaci-Dusseau andAndreaC.Arpaci-Dusseau
- Available(withseveraloptions)athttp://ostep.org
'Computer Science > 운영체제' 카테고리의 다른 글
| Deadlock (0) | 2022.05.10 |
|---|---|
| Synchronization 2 (0) | 2022.04.21 |
| Scheduling 2 (0) | 2022.04.12 |
| Scheduling 1 (0) | 2022.04.07 |
| Processes & Threads (0) | 2022.03.24 |




댓글